Linuxе…ұдә«еә“жҰӮиҝ°
е…ұдә«еә“жҳҜдёҖз§Қе°Ҷеә“еҮҪж•°жү“еҢ…жҲҗдёҖдёӘеҚ•е…ғдҪҝд№ӢиғҪеӨҹеңЁиҝҗиЎҢж—¶иў«еӨҡдёӘиҝӣзЁӢе…ұдә«зҡ„жҠҖжңҜ гҖӮ иҝҷз§ҚжҠҖжңҜиғҪеӨҹиҠӮзңҒзЈҒзӣҳз©әй—ҙе’ҢRAM гҖӮ
еңЁз»§з»ӯйҳҗиҝ°е…ұдә«еә“д№ӢеүҚ пјҢ е…ҲжқҘиҜҙиҜҙйқҷжҖҒеә“ пјҢ е®ғжҳҜжҜ”е…ұдә«еә“жӣҙж—©зҡ„еӯҳеңЁ гҖӮ йқҷжҖҒеә“д№ҹз§°дёәеҪ’жЎЈж–Ү件 пјҢ е®ғзҡ„дҪңз”Ёе°ұжҳҜе°ҶдёҖз»„з»Ҹеёёиў«з”ЁеҲ°зҡ„зӣ®ж Үж–Ү件组з»ҮиҝӣеҚ•дёӘеә“ж–Ү件 пјҢ иҝҷж ·д»ҘжқҘ пјҢ е°ұеҸҜд»ҘдҪҝз”Ёе®ғжқҘжһ„е»әеӨҡдёӘеҸҜжү§иЎҢзЁӢеәҸ пјҢ 并且еңЁжһ„е»әеҗ„дёӘеә”з”ЁзЁӢеәҸзҡ„ж—¶еҖҷж— йңҖйҮҚж–°зј–иҜ‘еҺҹжқҘзҡ„жәҗд»Јз Ғ гҖӮ
д»Һд»ҘдёҠзҡ„жҸҸиҝ°дёӯ пјҢ еҸҜд»ҘзңӢеҮә пјҢ йқҷжҖҒеә“еҝ…йЎ»е’ҢеҸҜжү§иЎҢж–Ү件дёҖиө·иў«иҝһжҺҘиҝӣзӣ®ж Үж–Ү件дёӯ пјҢ иҝҷж ·зҡ„иҜқ пјҢ дёҚеҗҢзҡ„еҸҜжү§иЎҢзЁӢеәҸдҪҝз”ЁдәҶзӣёеҗҢзҡ„зӣ®ж ҮжЁЎеқ—ж—¶ пјҢ жҜҸдёӘеҸҜжү§иЎҢзЁӢеәҸйғҪжңүиҮӘе·ұзҡ„дёҖд»ҪйқҷжҖҒеә“еүҜжң¬ пјҢ иҝҷж ·еҒҡжңүд»ҘдёӢеҮ дёӘзјәзӮ№пјҡ
- еӯҳеӮЁеҗҢдёҖзӣ®ж ҮжЁЎеқ—дјҡжөӘиҙ№зЈҒзӣҳз©әй—ҙ пјҢ 并且е®һйҷ…дёҠжөӘиҙ№зҡ„з©әй—ҙиҝҳжҳҜеҫҲеӨ§зҡ„ гҖӮ
- еҰӮжһңдҪҝз”ЁдәҶеҗҢдёҖжЁЎеқ—зҡ„еҮ дёӘдёҚеҗҢзҡ„еҸҜжү§иЎҢзЁӢеәҸеңЁеҗҢдёҖж—¶еҲ»иҝҗиЎҢ пјҢ йӮЈд№ҲжҜҸдёӘзЁӢеәҸдјҡзӢ¬з«Ӣең°еңЁиҷҡжӢҹеҶ…еӯҳдёӯдҝқеӯҳдёҖд»Ҫзӣ®ж ҮжЁЎеқ—зҡ„еүҜжң¬ пјҢ д»ҺиҖҢжҸҗй«ҳдәҶзі»з»ҹдёӯиҷҡжӢҹеҶ…еӯҳзҡ„дҪҝз”ЁйҮҸ гҖӮ
- иӢҘжҳҜйңҖиҰҒдҝ®ж”№йқҷжҖҒеә“дёӯзҡ„й”ҷиҜҜ пјҢ йӮЈд№ҲйңҖиҰҒйҮҚж–°з”ҹжҲҗйқҷжҖҒеә“ пјҢ еҶҚй“ҫжҺҘеҗҲ并еҲ°зӣ®ж Үж–Ү件дёӯ гҖӮ
- е…ұдә«еә“зҡ„е…ій”®жҖқжғіе°ұжҳҜзӣ®ж ҮжЁЎеқ—зҡ„еҚ•дёӘеүҜжң¬з”ұжүҖжңүйңҖиҰҒиҝҷдәӣжЁЎеқ—зҡ„зЁӢеәҸе…ұдә« пјҢ зӣ®ж ҮжЁЎеқ—дёҚдјҡиў«еӨҚеҲ¶еҲ°й“ҫжҺҘиҝҮзҡ„еҸҜжү§иЎҢж–Ү件дёӯ пјҢ иҖҢжҳҜ пјҢ еҪ“第дёҖдёӘйңҖиҰҒе…ұдә«еә“зҡ„жңЁеқ—зҡ„зЁӢеәҸеҗҜеҠЁж—¶ пјҢ еә“зҡ„еҚ•дёӘеүҜжң¬е°ұдјҡеңЁиҝҗиЎҢж—¶иў«еҠ иҪҪиҝӣеҶ…еӯҳ гҖӮ еҪ“еҗҺйқўдҪҝз”ЁеҗҢдёҖе…ұдә«еә“зҡ„е…¶д»–зЁӢеәҸеҗҜеҠЁж—¶ пјҢ е®ғ们дјҡдҪҝз”Ёе·Із»ҸеҠ иҪҪиҝӣеҶ…еӯҳзҡ„еә“зҡ„еүҜжң¬ гҖӮ дҪҝз”Ёе…ұдә«еә“ пјҢ е°ұж„Ҹе‘ізқҖеҸҜжү§иЎҢзЁӢеәҸйңҖиҰҒзҡ„зЈҒзӣҳз©әй—ҙе’ҢиҷҡжӢҹеҶ…еӯҳжӣҙе°‘дәҶ пјҢ иҝҷе°ұи§ЈеҶідәҶдёҖдёӘй—®йўҳ гҖӮ
- з”ұдәҺзӣ®ж ҮжЁЎеқ—жІЎжңүиў«еӨҚеҲ¶иҝӣеҸҜжү§иЎҢж–Ү件дёӯ пјҢ иҖҢжҳҜеңЁе…ұдә«еә“дёӯйӣҶдёӯз»ҙжҠӨ пјҢ еӣ жӯӨеңЁдҝ®ж”№зӣ®ж ҮжЁЎеқ—ж—¶ пјҢ ж— йңҖйҮҚж–°й“ҫжҺҘзЁӢеәҸ пјҢ з”ҡиҮіжӯЈеңЁиҝҗиЎҢзҡ„зЁӢеәҸжӯЈеңЁдҪҝз”ЁзҺ°жңүзүҲжң¬е…ұдә«еә“зҡ„ж—¶еҖҷд№ҹиғҪеӨҹиҝӣиЎҢиҝҷж ·зҡ„еҸҳжӣҙ гҖӮ
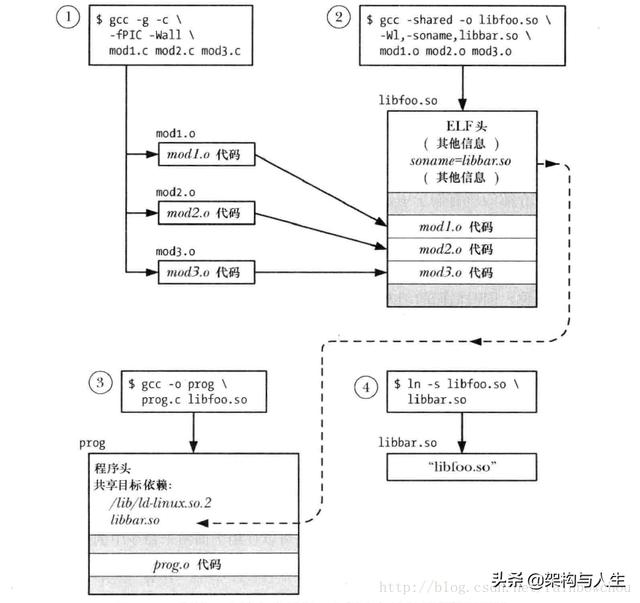 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫжҺҘдёӢжқҘзҡ„еҸҰдёҖеӣҫзӨәеҲҷжҳҜеҫҲеҪўиұЎе…·дҪ“ең°иҜҙжҳҺеҸҜеҲӣе»әзЁӢеәҸиў«еҠ иҪҪиҝӣеҶ…еӯҳж—¶жү§иЎҢпјҡ
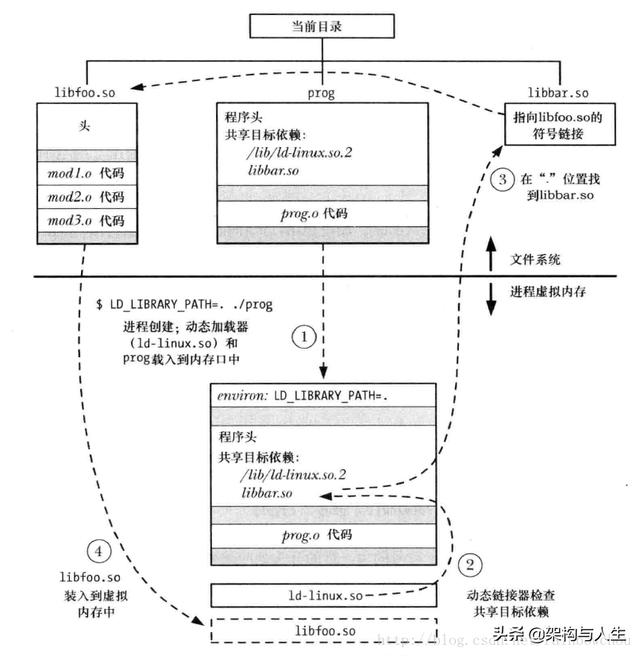 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ## дҪҝз”Ёе…ұдә«еә“зҡ„жңүз”Ёе·Ҙе…·
жҺҘдёӢжқҘд»Ӣз»ҚдёҖдәӣе’Ңе…ұдә«еә“зӣёе…ізҡ„жңүз”Ёе·Ҙе…·
- lddldd(еҲ—еҮәеҠЁжҖҒдҫқиө–)е‘Ҫд»ӨжҳҫзӨәдәҶдёҖдёӘзЁӢеәҸжүҖйңҖзҡ„е…ұдә«еә“ пјҢ жү§иЎҢеҰӮдёӢпјҡ
$ ldd xxx1е®ғдјҡд»Ҙlibrary-name => resolves-to-pathзҡ„еҪўејҸе°ҶзЁӢеәҸжүҖдҪҝз”Ёзҡ„еҠЁжҖҒеә“еҲ—дёҫеҮәжқҘ- objdump
- nm
е…ұдә«еә“зҡ„иҝҗиЎҢдёәдәҶиғҪеӨҹеңЁиҝҗиЎҢж—¶жүҫеҲ°е…ұдә«еә“ пјҢ еҠЁжҖҒй“ҫжҺҘеә“йҒөеҫӘдәҶдёҖз»„ж ҮеҮҶзҡ„жҗңзҙўи§„еҲҷ пјҢ е…¶дёӯеҢ…жӢ¬жҗңзҙўдёҖз»„еӨ§еӨҡж•°е…ұдә«еә“е®үиЈ…зҡ„зӣ®еҪ•(еҰӮ:/lib/ //usr/lib зӯү) пјҢ еҪ“然д№ҹеҸҜд»ҘеңЁз”ЁжҲ·иҮӘе®ҡд№үзҡ„зӣ®еҪ•дёӢжҗңзҙў пјҢ иҝҷдёҖзӮ№ пјҢ еҸҜд»ҘеҸӮиҖғзӣёе…іеҸӮиҖғ гҖӮ
е…ұдә«еә“зҡ„дёҖдәӣзү№жҖ§еҠЁжҖҒеҠ иҪҪеә“еҪ“дёҖдёӘеҸҜжү§иЎҢж–Ү件ејҖе§ӢиҝҗиЎҢеҗҺ пјҢ еҠЁжҖҒй“ҫжҺҘеҷЁдјҡеҠ иҪҪзЁӢеәҸзҡ„еҠЁжҖҒдҫқиө–еҲ—иЎЁдёӯзҡ„жүҖжңүе…ұдә«еә“ пјҢ дҪҶжңүдәӣж—¶еҖҷ пјҢ 延иҝҹеҠ иҪҪеә“жҳҜжҜ”иҫғжңүз”Ёзҡ„ пјҢ еҰӮеҸӘеңЁйңҖиҰҒзҡ„ж—¶еҖҷеҶҚеҠ иҪҪдёҖдёӘжҸ’件 пјҢ еҠЁжҖҒй“ҫжҺҘеҷЁжҳҜйҖҡиҝҮдёҖз»„еҮҪж•°жқҘе®һзҺ°зҡ„ гҖӮ е…ҲжҖ»дҪ“и®ӨиҜҶдёӢиҝҷдәӣеҮҪж•°пјҡ
dlopen();dlsym();dlclose();dlerror();жү“ејҖе…ұдә«еә“#include void *dlopen(const char * linfilename,int flag); д»ҘдёҠеҮҪж•°йҖҡиҝҮз”ЁжҲ·дј е…Ҙзҡ„ең°еқҖзӣ®еҪ• пјҢ жү“ејҖдәҶдёҖдёӘе…ұдә«еә“ пјҢ 并иҝ”еӣһдәҶдёҖдёӘдҫӣеҗҺз»ӯи°ғз”ЁдҪҝз”Ёзҡ„еҸҘжҹ„ гҖӮ
жҺЁиҚҗйҳ…иҜ»



















- Linux Kernel 5.10.5еҸ‘еёғпјҡзҰҒз”ЁFBCONеҠ йҖҹж»ҡеҠЁзү№жҖ§
- 35дәәе…ұз”ЁдёҖеә§еқҹпјҒж—Ҙжң¬жҺЁеҮәзҡ„вҖңе…ұдә«еқҹеў“вҖқзҒ«дәҶ
- еҫ®иҪҜзӣҳзӮ№12жңҲOneDriveжӣҙж–°пјҡзҪ‘йЎөз«ҜеҸҜеҲӣе»әе…ұдә«еә“зӯү
- Linux 5.11ејҖе§Ӣеӣҙз»•PCI Express 6.0иҝӣиЎҢж—©жңҹеҮҶеӨҮ
- FedoraжӯЈеңЁеҜ»жұӮеҚҸеҠ© еёҢжңӣеҠ еҝ«Linux 5.10 LTSеҶ…ж ёжөӢиҜ•иҝӣеәҰ
- Linux Mint 20.1 UlyssaзЁіе®ҡзүҲе·ІзЎ®е®ҡ延жңҹиҮі2021е№ҙеҲқеҸ‘еёғ
- иӢұзү№е°”Xe GPUеңЁLinux 5.11дёҠзҡ„жҖ§иғҪиЎЁзҺ°дёҚй”ҷ
- MIPSжһ¶жһ„еҺӮе•Ҷж—ҘжёҗејҸеҫ® LinuxжҠҘе‘Ҡе…¶жјҸжҙһйҒӯйҒҮеӣ°йҡҫ
- е“Ҳе•°еҮәиЎҢпјҡAPPжіЁеҶҢз”ЁжҲ·ж•°иҫҫ4дәҝпјҢе…ұдә«еҚ•иҪҰдёҡеҠЎиҰҶзӣ–и¶…460еҹҺ
- зӨҫеҢә|зӨҫеҢәеӣўиҙӯжҳҜжҒ¶жҳҜе–„пјҹдјҡжҲҗдёәдёӢдёҖдёӘе…ұдә«еҚ•иҪҰеҗ—пјҹдә’иҒ”зҪ‘е·ЁеӨҙвҖңжҺҗжһ¶вҖқжүҖдёәдҪ•еӣҫпјҹ