Googleзҡ„зҘһз»ҸзҪ‘з»ңиЎЁж јеӨ„зҗҶжЁЎеһӢTabNetд»Ӣз»Қ
Google Researchзҡ„TabNetдәҺ2019е№ҙеҸ‘еёғ пјҢ еңЁйў„еҚ°зЁҝдёӯиў«е®Јз§°дјҳдәҺиЎЁж јж•°жҚ®зҡ„зҺ°жңүж–№жі• гҖӮе®ғжҳҜеҰӮдҪ•е·ҘдҪңзҡ„ пјҢ еҸҲеҰӮдҪ•еҸҜд»Ҙе°қиҜ•е‘ўпјҹ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
иЎЁж јж•°жҚ®еҸҜиғҪжһ„жҲҗеҪ“д»ҠеӨ§еӨҡж•°дёҡеҠЎж•°жҚ® гҖӮиҖғиҷ‘иҜёеҰӮйӣ¶е”®дәӨжҳ“ пјҢ зӮ№еҮ»жөҒж•°жҚ® пјҢ е·ҘеҺӮдёӯзҡ„жё©еәҰе’ҢеҺӢеҠӣдј ж„ҹеҷЁ пјҢ 银иЎҢдҪҝз”Ёзҡ„KYC (Know Your Customer) дҝЎжҒҜжҲ–еҲ¶иҚҜе…¬еҸёдҪҝз”Ёзҡ„жЁЎеһӢз”ҹзү©зҡ„еҹәеӣ иЎЁиҫҫж•°жҚ®д№Ӣзұ»зҡ„дәӢжғ… гҖӮ
и®әж–Үз§°дёәTabNet: Attentive Interpretable Tabular LearningпјҲarxiv/1908.07442пјү пјҢ еҫҲеҘҪең°жҖ»з»“дәҶдҪңиҖ…жӯЈеңЁе°қиҜ•еҒҡзҡ„дәӢжғ… гҖӮ"Net"йғЁеҲҶе‘ҠиҜүжҲ‘们иҝҷжҳҜдёҖз§ҚзҘһз»ҸзҪ‘з»ң пјҢ "Attentive "йғЁеҲҶиЎЁзӨәе®ғжӯЈеңЁдҪҝз”ЁдёҖз§ҚжіЁж„ҸеҠӣжңәеҲ¶ пјҢ ж—ЁеңЁе®һзҺ°еҸҜи§ЈйҮҠжҖ§ пјҢ 并用дәҺиЎЁж јж•°жҚ®зҡ„жңәеҷЁеӯҰд№ гҖӮ
е®ғжҳҜеҰӮдҪ•е·ҘдҪңзҡ„пјҹTabNetдҪҝз”ЁдёҖз§ҚиҪҜеҠҹиғҪйҖүжӢ©е°ҶйҮҚзӮ№д»…ж”ҫеңЁеҜ№еҪ“еүҚзӨәдҫӢеҫҲйҮҚиҰҒзҡ„еҠҹиғҪдёҠ гҖӮиҝҷжҳҜйҖҡиҝҮйЎәеәҸзҡ„еӨҡжӯҘйӘӨеҶізӯ–жңәеҲ¶е®ҢжҲҗзҡ„ гҖӮеҚі пјҢ д»ҘеӨҡдёӘжӯҘйӘӨиҮӘдёҠиҖҢдёӢең°еӨ„зҗҶиҫ“е…ҘдҝЎжҒҜ гҖӮжӯЈеҰӮи®әж–ҮжүҖжҢҮеҮәзҡ„йӮЈж · пјҢ "иҮӘдёҠиҖҢдёӢе…іжіЁзҡ„жҖқжғіжҳҜд»ҺеӨ„зҗҶи§Ҷи§үе’ҢиҜӯиЁҖж•°жҚ®жҲ–ејәеҢ–еӯҰд№ дёӯеҫ—еҲ°зҡ„еҗҜеҸ‘ пјҢ еҸҜд»ҘеңЁй«ҳз»ҙиҫ“е…ҘдёӯжҗңзҙўдёҖе°ҸйғЁеҲҶзӣёе…ідҝЎжҒҜ гҖӮ "
е°Ҫз®Ўе®ғ们дёҺBERTзӯүжөҒиЎҢзҡ„NLPжЁЎеһӢдёӯдҪҝз”Ёзҡ„transformer жңүдәӣдёҚеҗҢ пјҢ дҪҶжү§иЎҢиҝҷз§ҚйЎәеәҸе…іжіЁзҡ„жһ„件еҚҙз§°дёәtransformer еқ— гҖӮиҝҷдәӣtransformer дҪҝз”ЁиҮӘжіЁж„ҸеҠӣжңәеҲ¶ пјҢ иҜ•еӣҫжЁЎжӢҹеҸҘеӯҗдёӯдёҚеҗҢеҚ•иҜҚд№Ӣй—ҙзҡ„дҫқиө–е…ізі» гҖӮ иҝҷйҮҢдҪҝз”Ёзҡ„transformerзұ»еһӢиҜ•еӣҫдҪҝз”Ё"иҪҜ"зү№жҖ§йҖүжӢ© пјҢ дёҖжӯҘдёҖжӯҘең°ж¶ҲйҷӨдёҺзӨәдҫӢж— е…ізҡ„йӮЈдәӣзү№жҖ§ пјҢ иҝҷжҳҜйҖҡиҝҮдҪҝз”ЁsparsemaxеҮҪж•°е®ҢжҲҗзҡ„ гҖӮ
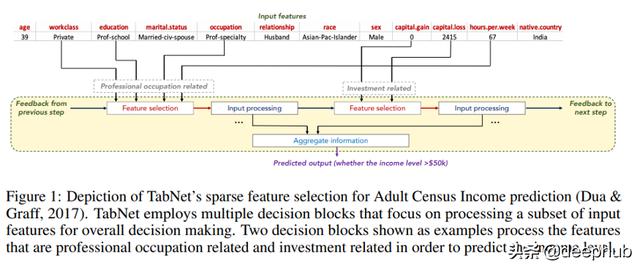
иҝҷзҜҮи®әж–Үзҡ„第дёҖдёӘеӣҫ пјҢ еҰӮдёӢйҮҚзҺ° пјҢ жҸҸз»ҳдәҶдҝЎжҒҜжҳҜеҰӮдҪ•иҒҡйӣҶиө·жқҘеҪўжҲҗйў„жөӢзҡ„ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
TabNetзҡ„дёҖдёӘеҘҪзү№жҖ§жҳҜе®ғдёҚйңҖиҰҒзү№жҖ§йў„еӨ„зҗҶ гҖӮ еҸҰдёҖдёӘеҺҹеӣ жҳҜ пјҢ е®ғе…·жңүеҶ…зҪ®зҡ„еҸҜи§ЈйҮҠжҖ§ пјҢ еҚідёәжҜҸдёӘзӨәдҫӢйҖүжӢ©жңҖзӣёе…ізҡ„зү№жҖ§ гҖӮ иҝҷж„Ҹе‘ізқҖжӮЁдёҚеҝ…еә”з”ЁеӨ–йғЁи§ЈйҮҠжЁЎеқ— пјҢ еҰӮshapжҲ–LIME гҖӮ
еңЁйҳ…иҜ»жң¬ж–Үж—¶ пјҢ иҰҒзҗҶи§ЈиҝҷдёӘжһ¶жһ„дёӯеҸ‘з”ҹдәҶд»Җд№Ҳ并дёҚе®№жҳ“ пјҢ дҪҶе№ёиҝҗзҡ„жҳҜ пјҢ е·Із»ҸеҸ‘иЎЁзҡ„д»Јз ҒзЁҚеҫ®жҫ„жё…дәҶдёҖдәӣй—®йўҳ пјҢ 并表жҳҺе®ғ并дёҚеғҸжӮЁеҸҜиғҪи®Өдёәзҡ„йӮЈж ·еӨҚжқӮ гҖӮ
жҲ‘жҖҺд№ҲдҪҝз”Ёе®ғ?зҺ°еңЁTabNetжңүдәҶжӣҙеҘҪзҡ„е®һзҺ° пјҢ еҰӮдёӢжүҖиҝ°:дёҖдёӘжҳҜPyTorchзҡ„жҺҘеҸЈ пјҢ е®ғжңүдёҖдёӘзұ»дјјscikitеӯҰд№ зҡ„жҺҘеҸЈ пјҢ иҝҳжңүдёҖдёӘжҳҜFastAIзҡ„жҺҘеҸЈ гҖӮ
ж №жҚ®дҪңиҖ…readmeжҸҸиҝ°иҰҒзӮ№еҰӮдёӢпјҡ
дёәжҜҸдёӘж•°жҚ®йӣҶеҲӣе»әж–°зҡ„train.csv пјҢ val.csvе’Ңtest.csvж–Ү件 пјҢ жҲ‘дёҚеҰӮиҜ»еҸ–ж•ҙдёӘж•°жҚ®йӣҶ并еңЁеҶ…еӯҳдёӯиҝӣиЎҢжӢҶеҲҶпјҲеҪ“然 пјҢ еҸӘиҰҒеҸҜиЎҢпјү пјҢ жүҖд»ҘжҲ‘еҶҷдәҶдёҖдёӘеңЁжҲ‘зҡ„д»Јз ҒдёӯдёәPandasжҸҗдҫӣдәҶж–°зҡ„иҫ“е…ҘеҠҹиғҪ гҖӮ
дҝ®ж”№data_helper.pyж–Ү件еҸҜиғҪйңҖиҰҒдёҖдәӣе·ҘдҪң пјҢ иҮіе°‘еңЁжңҖеҲқдёҚзЎ®е®ҡжӮЁиҰҒеҒҡд»Җд№Ҳд»ҘеҸҠеә”иҜҘеҰӮдҪ•е®ҡд№үеҠҹиғҪеҲ—ж—¶пјҲиҮіе°‘жҲ‘жҳҜиҝҷж ·пјү гҖӮ иҝҳжңүи®ёеӨҡеҸӮж•°йңҖиҰҒжӣҙж”№ пјҢ дҪҶе®ғ们дҪҚдәҺдё»и®ӯз»ғеҫӘзҺҜж–Ү件дёӯ пјҢ иҖҢдёҚжҳҜж•°жҚ®её®еҠ©еҷЁж–Ү件дёӯ гҖӮ жңүйүҙдәҺжӯӨ пјҢ жҲ‘иҝҳе°қиҜ•еңЁжҲ‘зҡ„д»Јз ҒдёӯжҰӮжӢ¬е’Ңз®ҖеҢ–жӯӨиҝҮзЁӢ гҖӮ
жҲ‘ж·»еҠ дәҶдёҖдәӣеҝ«йҖҹзҡ„д»Јз ҒжқҘиҝӣиЎҢи¶…еҸӮж•°дјҳеҢ– пјҢ дҪҶеҲ°зӣ®еүҚдёәжӯўд»…з”ЁдәҺеҲҶзұ» гҖӮ
иҝҳеҖјеҫ—дёҖжҸҗзҡ„жҳҜ пјҢ дҪңиҖ…жҸҗдҫӣзҡ„зӨәдҫӢд»Јз Ғд»…жҳҫзӨәдәҶеҰӮдҪ•иҝӣиЎҢеҲҶзұ» пјҢ иҖҢдёҚжҳҜеӣһеҪ’ пјҢ еӣ жӯӨз”ЁжҲ·д№ҹеҝ…йЎ»зј–еҶҷйўқеӨ–зҡ„д»Јз Ғ гҖӮ жҲ‘ж·»еҠ дәҶе…·жңүз®ҖеҚ•еқҮж–№иҜҜе·®жҚҹеӨұзҡ„еӣһеҪ’еҠҹиғҪ гҖӮ
дҪҝз”Ёе‘Ҫд»ӨиЎҢиҝҗиЎҢжөӢиҜ•python train_tabnet.py \ --csv-path data/adult.csv \ --target-name "<=50K" \ --categorical-features workclass,education,marital.status,\ occupation,relationship,race,sex,native.country\ --feature_dim 16 \ --output_dim 16 \ --batch-size 4096 \ --virtual-batch-size 128 \ --batch-momentum 0.98 \ --gamma 1.5 \ --n_steps 5 \ --decay-every 2500 \ --lambda-sparsity 0.0001 \ --max-steps 7700ејәеҲ¶жҖ§еҸӮж•°еҢ…жӢ¬--csv-pathпјҲжҢҮеҗ‘CSVж–Ү件зҡ„дҪҚзҪ®пјү пјҢ -target-nameпјҲе…·жңүйў„жөӢзӣ®ж Үзҡ„еҲ—зҡ„еҗҚз§°пјүе’Ң-category-featuesпјҲйҖ—еҸ·еҲҶйҡ”еҲ—иЎЁпјү еә”иҜҘи§ҶдёәеҲҶзұ»зҡ„еҠҹиғҪпјү гҖӮе…¶дҪҷиҫ“е…ҘеҸӮж•°жҳҜйңҖиҰҒй’ҲеҜ№жҜҸдёӘзү№е®ҡй—®йўҳиҝӣиЎҢдјҳеҢ–зҡ„и¶…еҸӮж•° гҖӮдҪҶжҳҜ пјҢ дёҠйқўжҳҫзӨәзҡ„еҖјзӣҙжҺҘеҸ–иҮӘTabNetи®әж–Ү пјҢ еӣ жӯӨдҪңиҖ…е·Із»Ҹй’ҲеҜ№жҲҗдәәжҷ®жҹҘж•°жҚ®йӣҶеҜ№е…¶иҝӣиЎҢдәҶдјҳеҢ– гҖӮ
жҺЁиҚҗйҳ…иҜ»

















- жӢңжӢңжү«жҸҸд»ӘпјҒеҫ®дҝЎжү“ејҖиҝҷдёӘеҠҹиғҪпјҢж–ҮжЎЈиЎЁж јжү«дёҖжү«з§’еҸҳз”өеӯҗжЎЈ
- Google AIе»әз«ӢдәҶдёҖдёӘиғҪеӨҹеҲҶжһҗзғҳз„ҷйЈҹи°ұзҡ„жңәеҷЁеӯҰд№ жЁЎеһӢ
- дёүжҳҹе…¬еёғ2021е№ҙж¬ҫз”өи§Ҷйҳөе®№пјҡеұҸ幕жҠҖжңҜеӨ§еҚҮзә§ ж•ҙеҗҲGoogle DuoзӯүжңҚеҠЎ
- Google Assistantж–°е№ҙж–°жҠҖиғҪпјҡдёәдҪ е”ұдёҠдёҖйҰ–вҖңж–°е№ҙжӯҢвҖқ
- Google ChromeејҖеҸ‘еӣўйҳҹжӯЈжҺўзҙўйҖҡиҝҮжү©еӨ§жөҸи§ҲеҷЁзј“еӯҳи§ЈеҶіжҖ§иғҪй—®йўҳ
- vivo Y31ж–°жңәзҺ°иә«Google PlayпјҒе°ҶжҗӯиҪҪдәҶйӘҒйҫҷ662иҠҜзүҮ
- Googleе®•жңә45еҲҶй’ҹпјҢе…Ёдё–з•ҢзҪ‘еҸӢжҖҘз–ҜдәҶ
- жӢҚжӢҚиғҢеҢ…зҺ©иҪ¬жӮЁзҡ„жүӢжңәпјҢз”ұGoogleдёҺж–°з§ҖдёҪжҷәиғҪзәӨз»ҙжҠҖжңҜ
- жңҖеүҚзәҝпҪңGoogle PayејҖеҗҜвҖңи–…зҫҠжҜӣвҖқжЁЎејҸпјҢ继з»ӯиҝӣж”»зҫҺеӣҪж”Ҝд»ҳеёӮеңә
- Google Playжӣқе…үдёүжҳҹGalaxy M02s иҜҒе®һGalaxy A02sжҚўзҡ®