жө…и°Ҳ MaxCompute иө„жәҗ规еҲ’з®ЎзҗҶеҸҠиҜ„дј°( еӣӣ )
Step4пјҡеҫ—еҲ°MaxComputeи®Ўз®—иө„жәҗCUж•°йҮҸпјҡ202 CPUж ёж•° *е°Ҹж—¶ / 5е°Ҹж—¶ = 40.2 coresж ёж•° пјҢ д№ҹе°ұжҳҜиҮіе°‘йңҖиҰҒ41 CU гҖӮ еӣ жӯӨе»әи®®е®ўжҲ·иҙӯд№°и®Ўз®—иө„жәҗCUйҮҸдёә 41*2 = 82 CUж•°йҮҸ гҖӮ
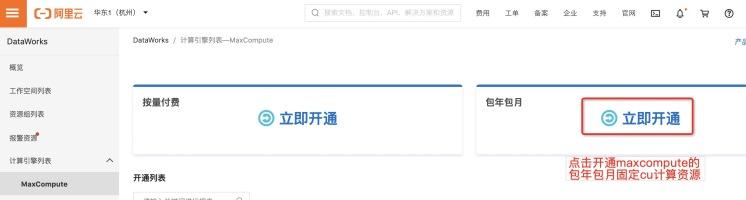
ж №жҚ®йў„дј°и®Ўз®—з»“жһң пјҢ жҲ‘们дёәе®ўжҲ·жҺЁиҚҗиҙӯд№°зҡ„еҢ…е№ҙеҢ…жңҲеӣәе®ҡCUйҮҸдёә82дёӘ гҖӮ е…ҲејҖйҖҡMaxCompute и®Ўз®—иө„жәҗquota group иө„жәҗз»„зҡ„еҢ…е№ҙеҢ…жңҲеӣәе®ҡCUиө„жәҗпјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
然еҗҺй…ҚзҪ®жҖ»CUйҮҸдёә82дёӘ гҖӮ
еӣӣгҖҒжө…и°ҲMaxCompute group quota иө„жәҗеҲ’еҲҶ方法笔иҖ…еңЁз¬¬3з« иҠӮиҜҰз»Ҷд»Ӣз»ҚеҰӮдҪ•ж №жҚ®жңҖиҝ‘дёҖж®өж—¶й—ҙзҡ„CUж¶ҲиҖ—жғ…еҶө пјҢ йў„дј°еҫ—еҲ°MaxCompute и®Ўз®—иө„жәҗCUж•°йҮҸ гҖӮ иҙӯд№°зҡ„MaxCompute quota groupиө„жәҗеұһдәҺвҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқ пјҢ зұ»дјјдәҺејҖжәҗhadoop yarnзҡ„rootиө„жәҗйҳҹеҲ— гҖӮ еңЁе®һйҷ…йЎ№зӣ®ејҖеҸ‘иҝҮзЁӢдёӯ пјҢ иҝҳйңҖиҰҒе°ҶвҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқеҶҚз»ҶеҲҶдёәиӢҘе№ІдёӘвҖңеӯҗquota groupиө„жәҗз»„вҖқ гҖӮ еҪ“然 пјҢ дёҖиҲ¬жғ…еҶөдёӢе»әи®®1дёӘMaxCompute project еҲ’еҲҶ1дёӘеӯҗquota groupиө„жәҗз»„ гҖӮ еҰӮдҪ•е°ҶвҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқеҲ’еҲҶдёәиӢҘе№ІдёӘеӯҗquota groupиө„жәҗз»„пјҹиҝҷжҳҜжң¬з« иҠӮйңҖиҰҒиҜҰз»Ҷд»Ӣз»Қзҡ„еҶ…е®№ гҖӮ
4.1 fuxiдјҸзҫІиө„жәҗи°ғеәҰзі»з»ҹеҺҹзҗҶз®Җд»Ӣ
дёәдәҶдҫҝдәҺиҜ»иҖ…зҗҶfuxiи°ғеәҰзі»з»ҹе…ідәҺиө„жәҗз»„зҡ„иө„жәҗеҲҶй…Қе’Ңиө„жәҗжҠўеҚ жңәеҲ¶ пјҢ жң¬ж–Үд»ҘејҖжәҗhadoop yarnиө„жәҗйҳҹеҲ—иҝӣиЎҢзұ»жҜ” гҖӮ MaxComputeзҡ„вҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқзұ»дјјдәҺyarnзҡ„rootиө„жәҗйҳҹеҲ— пјҢ иҝҷйғЁеҲҶи®Ўз®—иө„жәҗеұһдәҺвҖңжҖ»и®Ўз®—иө„жәҗз»„вҖқ пјҢ йңҖиҰҒе°ҶжҖ»иө„жәҗз»„иҝӣиЎҢз»ҶеҲҶ гҖӮ
еҒҮи®ҫжҲ‘们иҙӯд№°зҡ„вҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқеҢ…еҗ«DtдёӘCUиө„жәҗ пјҢ 然еҗҺвҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқиў«еҲ’еҲҶдәҶnдёӘеӯҗиө„жәҗз»„D1гҖҒD2 вҖҰвҖҰ DnгҖӮ иҝҷnдёӘиө„жәҗз»„еҝ…йЎ»и®ҫзҪ®дёӨдёӘйҮҚиҰҒеҸӮж•°пјҡиө„жәҗз»„зҡ„вҖңйў„з•ҷCUжңҖе°Ҹй…ҚйўқвҖқminD1гҖҒminD2вҖҰвҖҰminDn пјҢ д»ҘеҸҠвҖңйў„з•ҷCUжңҖеӨ§й…ҚйўқвҖқ maxD1гҖҒmaxD2вҖҰвҖҰmaxDn гҖӮ иҝҷnдёӘиө„жәҗз»„еҝ…йЎ»ж»Ўи¶ід»ҘдёӢжқЎд»¶пјҡ
- minD1 + minD2 + вҖҰвҖҰ + minDn = Dt
- еҜ№дәҺд»»ж„Ҹзҡ„еӯҗиө„жәҗз»„зҡ„maxDi пјҢ maxDi <= Dt
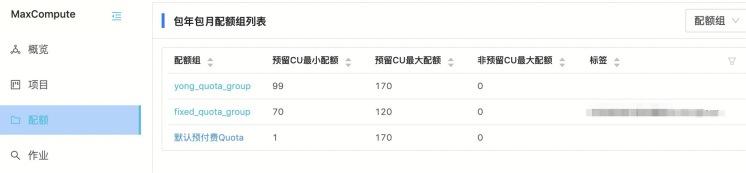
еҰӮдёӢеӣҫжүҖзӨә пјҢ 170дёӘCUиө„жәҗйҮҸзҡ„вҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқеҲ’еҲҶдәҶдёӨдёӘеӯҗиө„жәҗз»„пјҡ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫд»ҺдёҠеӣҫжҲ‘们зңӢеҲ° пјҢ еҲ’еҲҶзҡ„дёӨдёӘеӯҗиө„жәҗз»„yong_quota_group е’Ң fixed_quota_groupи®ҫзҪ®зҡ„жңҖе°ҸCUй…ҚйўқгҖҒжңҖеӨ§CUй…Қйўқ пјҢ ж»Ўи¶ідёҠиҝ°дёӨдёӘжқЎд»¶ гҖӮ
4.2 MaxComputeи®Ўз®—иө„жәҗжҠўеҚ жңәеҲ¶
жҢүз…§4.1д»Ӣз»Қзҡ„еҶ…е®№ пјҢ иӢҘе№ІдёӘеӯҗиө„жәҗз»„зҡ„maxжңҖеӨ§CUй…ҚйўқйғҪеҸҜд»Ҙи®ҫзҪ®дёәвҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқ пјҢ йӮЈд№ҲдёҖж—ҰжүҖжңүиө„жәҗз»„еҜ№еә”зҡ„MaxCompute projectйғҪз–ҜзӢӮең°иҝҗиЎҢд»»еҠЎ пјҢ йӮЈд№Ҳеҝ…然еӯҳеңЁиө„жәҗжҠўеҚ зҡ„й—®йўҳ гҖӮ жҢүз…§й»ҳи®Ө规еҲҷ пјҢ MaxComputeиө„жәҗз»„зҡ„иө„жәҗжҠўеҚ жҢүз…§вҖңfair schedulingвҖқе…¬е№іи°ғеәҰжңәеҲ¶ пјҢ е…ҲжҸҗдәӨзҡ„д»»еҠЎдјҳе…ҲиҺ·еҸ–CUиө„жәҗ гҖӮ йӮЈд№Ҳ пјҢ еҰӮжһңжҹҗдёӘMaxCompute projectжҸҗдәӨи¶…еӨ§еһӢд»»еҠЎ пјҢ еҝ…然е°ҶдјҡжҠҠCUиө„жәҗж¶ҲиҖ—ж®Ҷе°Ҫ гҖӮ жӯӨж—¶ пјҢ е…¶д»–иө„жәҗз»„еҜ№еә”зҡ„MaxCompute projectжҸҗдәӨзҡ„д»»еҠЎе°Ҷдјҡеӣ дёәж— жі•иҺ·еҸ–еҲ°CUиө„жәҗиҖҢиў«йҳ»еЎһ гҖӮ
еҰӮдҪ•жӣҙеҠ е®ҢзҫҺең°еҲ’еҲҶquota groupиө„жәҗз»„ пјҢ 并且дёәжҜҸдёӘиө„жәҗз»„еҲҶй…ҚжңҖеҗҲзҗҶзҡ„ minиө„жәҗй…ҚйўқгҖҒmaxиө„жәҗй…Қйўқпјҹ еҰӮдҪ•з»“еҗҲе®һйҷ…йЎ№зӣ®йңҖжұӮ пјҢ еҗҲзҗҶе®үжҺ’д»»еҠЎиҝҗиЎҢзҡ„е…ҲеҗҺйЎәеәҸгҖҒд»ҘеҸҠд»»еҠЎиҝҗиЎҢи°ғеәҰзҡ„дҫқиө–е…ізі»пјҹиҝҷжҳҜеҲ’еҲҶеӯҗquota groupиө„жәҗз»„йңҖиҰҒиҖғиҷ‘зҡ„йҮҚзӮ№еӣ зҙ гҖӮ
4.3 quota groupиө„жәҗз»„еҲ’еҲҶ
еңЁз¬¬3з« иҠӮиҜҰз»Ҷд»Ӣз»ҚеҰӮдҪ•йў„дј°и®Ўз®—дјҒдёҡе®ўжҲ·йңҖиҰҒиҙӯд№°зҡ„еҢ…е№ҙеҢ…жңҲйў„з•ҷCUйҮҸ пјҢ д№ҹе°ұжҳҜ вҖңй»ҳи®Өйў„д»ҳиҙ№QuotaвҖқ пјҢ жҜ”еҰӮ3.3.3з« иҠӮзҡ„е®һйҷ…жЎҲдҫӢйҮҢйқўд»Ӣз»Қзҡ„170дёӘCU гҖӮ дёӢдёҖжӯҘе°ұжҳҜеҲӣе»әеӯҗquota groupиө„жәҗз»„ пјҢ 并дёәжҜҸдёӘquota groupеҲҶй…Қ minгҖҒmaxиө„жәҗйҮҸ гҖӮ 笔иҖ…з»“еҗҲеӨҡе№ҙhadoop yarnиө„жәҗеҲҶй…Қз»ҸйӘҢ пјҢ д»ҘеҸҠдҪҝз”ЁMaxComputeзҡ„дёҖдәӣз»ҸйӘҢ пјҢ жҖ»з»“дәҶдёҖдәӣе®һйҷ…зҡ„з»ҸйӘҢ гҖӮ
жҺЁиҚҗйҳ…иҜ»












![[еҠұеҝ—и§Ҷйў‘зҹӯзүҮ]еҒҡеҘҪдәӢпјҢеҫ®з¬‘жҢӮж»ЎдёӨи…®жүҚжҳҜжӯЈйҒ“пјҒпјҢж—©е®үеҝғиҜӯпјҡеӯҳеҘҪеҝғ](https://imgcdn.toutiaoyule.com/20200503/20200503054140414532a_t.jpeg)




- еҚҺдә‘еӨ§е’–иҜҙ дә‘и®Ўз®—дә‘иҝҗз»ҙжө…и°Ҳ
- ж¶ҲжҒҜ|еҲҳдҪңиҷҺпјҡд»Ҡе№ҙе°ҶеңЁеҪұеғҸеҠӣжҠ•е…Ҙе·ЁеӨ§иө„жәҗ еҠӣдәүеҒҡеҲ°е…Ёзҗғ第дёҖ
- иҒҡз„ҰеҲӣж–°ж ёеҝғиө„жәҗ зҺҜеҚҺиҘҝеҒҘеә·дә§дёҡдёҖдҪ“еҢ–з»јеҗҲ科жҠҖеҲӣж–°жңҚеҠЎе№іеҸ°вҖңдёҠзәҝвҖқ
- йў„жҠҘ|иҮӘ然иө„жәҗйғЁеӣҪ家жө·жҙӢзҺҜеўғйў„жҠҘдёӯеҝғжҺЁеҮәе°ҸзЁӢеәҸ
- иө„жәҗ|еҫ®иҪҜдәҡжҙІз ”究йҷўеҸ‘еёғејҖжәҗе№іеҸ°вҖңзҫӨзӯ– MAROвҖқз”ЁдәҺеӨҡжҷәиғҪдҪ“иө„жәҗи°ғеәҰдјҳеҢ–
- зү©жөҒеӣҪ家е·ҘзЁӢе®һйӘҢе®Өеҝ«д»¶зү©жөҒиө„жәҗе…ұдә«жңҚеҠЎеә”з”ЁзӨәиҢғеҹәең°еңЁйҮ‘жҳҢжҸӯзүҢ
- иӢҸе®Ғ|зҺ©еҮәи·Ёз•ҢиҗҘй”Җж–°й«ҳеәҰпјҢиӢҸе®Ғиө„жәҗејҖж”ҫиөӢиғҪеҠ©еҠӣз”ЁжҲ·ејҖеҗҜжҷәж…§з”ҹжҙ»
- иө„жәҗ|еҫ®иҪҜдәҡз ”йҷўејҖжәҗMAROе№іеҸ°пјҡи§ЈеҶіеӨҡиЎҢдёҡиө„жәҗдјҳеҢ–и°ғеәҰй—®йўҳ
- еӨ§зҘһдҪҝз”ЁPythonзҲ¬еҸ–еҫ®дҝЎзҫӨйҮҢзҡ„зҷҫеәҰдә‘иө„жәҗ
- жө…и°Ҳе…ұдә«з»ҸжөҺ