зӮ№дә‘еҲҶзұ»зҡ„иҮӘеҠЁж”ҫеӨ§жЎҶжһ¶ PointAugment
ж‘ҳиҰҒжң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°зҡ„иҮӘеҠЁж”ҫеӨ§жЎҶжһ¶ PointAugment пјҢ еңЁи®ӯз»ғеҲҶзұ»зҪ‘з»ңж—¶ пјҢ иҮӘеҠЁдјҳеҢ–е’Ңж”ҫеӨ§зӮ№дә‘ж ·жң¬ пјҢ д»Ҙдё°еҜҢж•°жҚ®зҡ„еӨҡж ·жҖ§ гҖӮ дёҺзҺ°жңүзҡ„дәҢз»ҙеӣҫеғҸиҮӘеҠЁж”ҫеӨ§ж–№жі•дёҚеҗҢ пјҢ PointAugment жҳҜдёҖз§Қж ·жң¬ж„ҹзҹҘзҡ„ж–№жі• пјҢ йҮҮз”ЁдёҖз§ҚеҜ№жҠ—жҖ§еӯҰд№ зӯ–з•ҘжқҘиҒ”еҗҲдјҳеҢ–ж”ҫеӨ§еҷЁзҪ‘з»ңе’ҢеҲҶзұ»еҷЁзҪ‘з»ң пјҢ дҪҝж”ҫеӨ§еҷЁиғҪеӨҹеӯҰд№ дә§з”ҹжңҖйҖӮеҗҲеҲҶзұ»еҷЁзҡ„ж”ҫеӨ§ж ·жң¬ гҖӮ жӯӨеӨ– пјҢ жһ„йҖ дәҶдёҖдёӘеёҰеҪўзҠ¶еҸҳжҚўе’ҢзӮ№дҪҚ移зҡ„еҸҜеӯҰд№ зӮ№ж”ҫеӨ§еҮҪж•° пјҢ е№¶ж №жҚ®еҲҶзұ»еҷЁзҡ„еӯҰд№ иҝӣеәҰ пјҢ зІҫеҝғи®ҫи®ЎжҚҹеӨұеҮҪж•°жқҘйҮҮз”Ёж”ҫеӨ§ж ·жң¬ гҖӮ еӨ§йҮҸе®һйӘҢд№ҹиҜҒе®һдәҶ PointAugment зҡ„жңүж•ҲжҖ§е’ҢйІҒжЈ’жҖ§ пјҢ еҸҜд»Ҙж”№е–„еҗ„з§ҚзҪ‘з»ңзҡ„еҪўзҠ¶еҲҶзұ»е’ҢжЈҖзҙўжҖ§иғҪ гҖӮ
1пјҺд»Ӣз»ҚгҖҗзӮ№дә‘еҲҶзұ»зҡ„иҮӘеҠЁж”ҫеӨ§жЎҶжһ¶ PointAugmentгҖ‘иҝ‘ 24 е№ҙжқҘ пјҢ дәәеҜ№дёүз»ҙзҘһз»ҸзҪ‘з»ңзҡ„з ”з©¶е…ҙи¶ЈдёҺж—Ҙдҝұеўһ гҖӮ еҸҜйқ ең°и®ӯз»ғзҪ‘з»ңйҖҡеёёдҫқиө–дәҺж•°жҚ®зҡ„еҸҜз”ЁжҖ§е’ҢеӨҡж ·жҖ§ гҖӮ 然иҖҢ пјҢ дёҺ ImageNet е’Ң MS-COCO ж•°жҚ®йӣҶзӯүдәҢз»ҙеӣҫеғҸеҹәеҮҶжөӢиҜ•дёҚеҗҢ пјҢ 3D ж•°жҚ®йӣҶзҡ„ж•°йҮҸйҖҡеёёиҰҒе°Ҹеҫ—еӨҡ пјҢ ж Үзӯҫж•°йҮҸзӣёеҜ№иҫғе°‘ пјҢ еӨҡж ·жҖ§жңүйҷҗ гҖӮ дҫӢеҰӮ пјҢ ModelNet40 жҳҜ 3D зӮ№дә‘еҲҶзұ»жңҖеёёз”Ёзҡ„еҹәеҮҶд№ӢдёҖ пјҢ еҸӘжңү 40 дёӘзұ»еҲ«зҡ„ 12311 дёӘжЁЎеһӢ гҖӮ жңүйҷҗзҡ„ж•°жҚ®йҮҸе’ҢеӨҡж ·жҖ§еҸҜиғҪеҜјиҮҙиҝҮжӢҹеҗҲй—®йўҳ пјҢ иҝӣиҖҢеҪұе“ҚзҪ‘з»ңзҡ„жіӣеҢ–иғҪеҠӣ гҖӮ зӣ®еүҚ пјҢ ж•°жҚ®ж”ҫеӨ§пјҲDAпјүжҳҜдёҖз§Қйқһеёёжҷ®йҒҚзҡ„зӯ–з•Ҙ пјҢ йҖҡиҝҮдәәе·ҘеўһеҠ и®ӯз»ғж ·жң¬зҡ„ж•°йҮҸе’ҢеӨҡж ·жҖ§жқҘйҒҝе…ҚиҝҮеәҰжӢҹеҗҲ пјҢ жҸҗй«ҳзҪ‘з»ңжіӣеҢ–иғҪеҠӣ гҖӮ еҜ№дәҺдёүз»ҙзӮ№дә‘ пјҢ з”ұдәҺи®ӯз»ғж ·жң¬ж•°йҮҸжңүйҷҗ пјҢ дё”еңЁ 3D дёӯжңүе·ЁеӨ§зҡ„ж”ҫеӨ§з©әй—ҙ пјҢ дј з»ҹзҡ„ DA зӯ–з•Ҙ[23 пјҢ 24]йҖҡеёёеҸӘжҳҜеңЁдёҖдёӘе°Ҹзҡ„гҖҒеӣәе®ҡзҡ„йў„е…Ҳе®ҡд№үзҡ„ж”ҫеӨ§иҢғеӣҙеҶ…йҡҸжңәжү°еҠЁиҫ“е…ҘзӮ№дә‘ пјҢ д»ҘдҝқжҢҒзұ»ж Үзӯҫ гҖӮ
е°Ҫз®Ўиҝҷз§Қдј з»ҹзҡ„ DA ж–№жі•еҜ№зҺ°жңүзҡ„еҲҶзұ»зҪ‘з»ңжңүж•Ҳ пјҢ дҪҶеҸҜиғҪеҜјиҮҙи®ӯз»ғдёҚи¶і пјҢ еҰӮдёӢжүҖиҝ° гҖӮ йҰ–е…Ҳ пјҢ зҺ°жңүзҡ„ж·ұйғЁдёүз»ҙзӮ№дә‘еӨ„зҗҶж–№жі•е°ҶзҪ‘з»ңи®ӯз»ғе’Ңж•°жҚ®йҮҮйӣҶи§ҶдёәдёӨдёӘзӢ¬з«Ӣзҡ„йҳ¶ж®ө пјҢ жІЎжңүиҒ”еҗҲдјҳеҢ– пјҢ дҫӢеҰӮеҸҚйҰҲи®ӯз»ғз»“жһңд»Ҙж”ҫеӨ§ DA гҖӮ еӣ жӯӨ пјҢ и®ӯз»ғеҗҺзҡ„зҪ‘з»ңеҸҜиғҪжҳҜж¬Ўдјҳзҡ„ гҖӮ е…¶ж¬Ў пјҢ зҺ°жңүж–№жі•еҜ№жүҖжңүиҫ“е…ҘзӮ№дә‘ж ·жң¬еә”з”ЁзӣёеҗҢзҡ„еӣәе®ҡж”ҫеӨ§иҝҮзЁӢ пјҢ еҢ…жӢ¬ж—ӢиҪ¬гҖҒзј©ж”ҫе’Ң/жҲ–жҠ–еҠЁ гҖӮ еңЁж”ҫеӨ§иҝҮзЁӢдёӯеҝҪз•ҘдәҶж ·жң¬зҡ„еҪўзҠ¶еӨҚжқӮеәҰ пјҢ дҫӢеҰӮ пјҢ зҗғдҪ“ж— и®әеҰӮдҪ•ж—ӢиҪ¬йғҪдҝқжҢҒдёҚеҸҳ пјҢ дҪҶеӨҚжқӮеҪўзҠ¶еҸҜиғҪйңҖиҰҒжӣҙеӨ§зҡ„ж—ӢиҪ¬ гҖӮ еӣ жӯӨ пјҢ дј з»ҹзҡ„ DA еҜ№дәҺеўһеҠ и®ӯз»ғж ·жң¬еҸҜиғҪжҳҜеӨҡдҪҷзҡ„жҲ–дёҚе……еҲҶзҡ„ гҖӮ
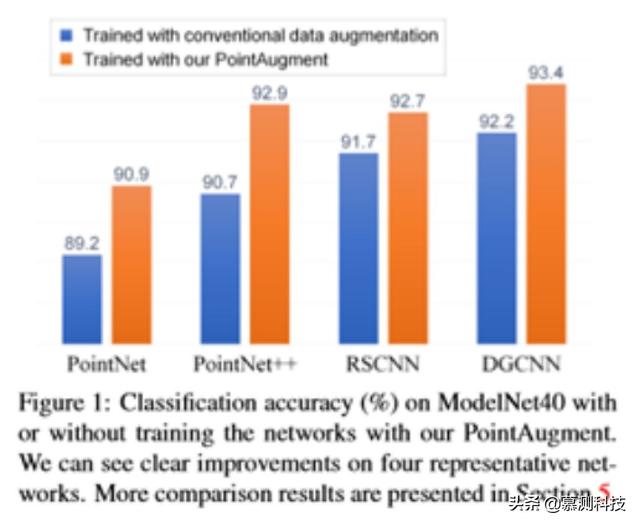
дёәдәҶж”№иҝӣзӮ№дә‘ж ·жң¬зҡ„ж”ҫеӨ§ пјҢ жҸҗеҮәдәҶдёҖз§Қж–°зҡ„дёүз»ҙзӮ№дә‘иҮӘеҠЁж”ҫеӨ§жЎҶжһ¶ PointAugment пјҢ 并еұ•зӨәдәҶе…¶ж”ҫеӨ§еҪўзҠ¶еҲҶзұ»зҡ„жңүж•ҲжҖ§пјӣи§Ғеӣҫ 1 гҖӮ дёҺд»ҘеүҚзҡ„дәҢз»ҙеӣҫеғҸдёҚеҗҢ пјҢ PointAugment еӯҰд№ з”ҹжҲҗзү№е®ҡдәҺеҚ•дёӘж ·жң¬зҡ„ж”ҫеӨ§еҮҪж•° гҖӮ жӯӨеӨ– пјҢ еҸҜеӯҰд№ зҡ„ж”ҫеӨ§еҮҪж•°еҗҢж—¶иҖғиҷ‘дәҶеҪўзҠ¶еҸҳжҚўе’ҢзӮ№ж–№еҗ‘дҪҚ移 пјҢ иҝҷдёҺдёүз»ҙзӮ№дә‘ж ·жң¬зҡ„зү№еҫҒжңүе…і гҖӮ жӯӨеӨ– пјҢ PointAugment йҖҡиҝҮдёҖз§ҚеҜ№жҠ—жҖ§еӯҰд№ зӯ–з•Ҙ пјҢ е°Ҷж”ҫеӨ§зҪ‘з»ңпјҲaugmentorпјүдёҺеҲҶзұ»зҪ‘з»ңпјҲClassifierпјүиҝӣиЎҢз«ҜеҲ°з«Ҝзҡ„и®ӯз»ғ пјҢ д»ҺиҖҢдёҺзҪ‘з»ңи®ӯз»ғе…ұеҗҢдјҳеҢ–ж”ҫеӨ§иҝҮзЁӢ гҖӮ йҖҡиҝҮе°ҶеҲҶзұ»жҚҹеӨұдҪңдёәеҸҚйҰҲ пјҢ ж”ҫеӨ§еҷЁеҸҜд»ҘеӯҰд№ йҖҡиҝҮжү©еӨ§зұ»еҶ…ж•°жҚ®еҸҳеҢ–жқҘдё°еҜҢиҫ“е…Ҙж ·жң¬ пјҢ иҖҢеҲҶзұ»еҷЁеҸҜд»ҘеӯҰд№ йҖҡиҝҮжҸҗеҸ–дёҚж•Ҹж„ҹзү№еҫҒжқҘе…ӢжңҚиҝҷдёҖй—®йўҳ гҖӮ еҸ—зӣҠдәҺиҝҷз§ҚеҜ№жҠ—жҖ§еӯҰд№ пјҢ ж”ҫеӨ§еҷЁеҸҜд»ҘеӯҰд№ з”ҹжҲҗеңЁдёҚеҗҢи®ӯз»ғйҳ¶ж®өжңҖйҖӮеҗҲеҲҶзұ»иҖ…зҡ„ж”ҫеӨ§ж ·жң¬ пјҢ д»ҺиҖҢжңҖеӨ§йҷҗеәҰең°жҸҗй«ҳеҲҶзұ»иҖ…зҡ„иғҪеҠӣ гҖӮ дҪңдёәжҺўзҙў 3D зӮ№дә‘иҮӘеҠЁж”ҫеӨ§зҡ„第дёҖж¬Ўе°қиҜ• пјҢ еұ•зӨәдәҶйҖҡиҝҮз”Ё PointAugment еҸ–д»Јдј з»ҹзҡ„ DA пјҢ еҸҜд»ҘеңЁеӣӣдёӘе…·жңүд»ЈиЎЁжҖ§зҡ„зҪ‘з»ңдёҠе®һзҺ°еҜ№ ModelNet40пјҲи§Ғеӣҫ 1пјүе’Ң SHREC16пјҲи§Ғ第 5 иҠӮпјүж•°жҚ®йӣҶзҡ„еҪўзҠ¶еҲҶзұ»зҡ„жҳҺжҳҫж”№иҝӣ пјҢ еҢ…жӢ¬ PointNetгҖҒPointNet++ пјҢ RSCNN е’Ң DGCNN гҖӮ жӯӨеӨ– пјҢ иҝҳеұ•зӨәдәҶ PointAugment еңЁеҪўзҠ¶жЈҖзҙўдёҠзҡ„жңүж•ҲжҖ§ пјҢ 并иҜ„дј°дәҶе…¶йІҒжЈ’жҖ§гҖҒжҚҹеӨұй…ҚзҪ®е’ҢжЁЎеқ—еҢ–и®ҫи®Ў гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
2пјҺзӣёе…іе·ҘдҪңпјҲ1пјүеӣҫеғҸж•°жҚ®ж”ҫеӨ§
и®ӯз»ғж•°жҚ®еҜ№ж·ұеұӮзҘһз»ҸзҪ‘з»ңеӯҰд№ жү§иЎҢд»»еҠЎиө·зқҖйқһеёёйҮҚиҰҒзҡ„дҪңз”Ё гҖӮ 然иҖҢ пјҢ дёҺзҺ°е®һдё–з•Ңзҡ„еӨҚжқӮжҖ§зӣёжҜ” пјҢ и®ӯз»ғж•°жҚ®зҡ„ж•°йҮҸеҫҖеҫҖжҳҜжңүйҷҗзҡ„ пјҢ еӣ жӯӨз»ҸеёёйңҖиҰҒж•°жҚ®ж”ҫеӨ§жқҘж”ҫеӨ§и®ӯз»ғйӣҶ пјҢ жңҖеӨ§йҷҗеәҰең°еҲ©з”Ёи®ӯз»ғж•°жҚ®еӯҰд№ еҲ°зҡ„зҹҘиҜҶ гҖӮ дёҖдәӣе·ҘдҪңжІЎжңүйҡҸжңәеҸҳжҚўи®ӯз»ғж•°жҚ®ж ·жң¬[42,41] пјҢ иҖҢжҳҜе°қиҜ•еҲ©з”ЁеӣҫеғҸз»„еҗҲ[12]гҖҒз”ҹжҲҗеҜ№жҠ—зҪ‘з»ң[31,27]гҖҒиҙқеҸ¶ж–ҜдјҳеҢ–[35]е’ҢжҪңеңЁз©әй—ҙдёӯзҡ„еӣҫеғҸжҸ’еҖј[4,16,2]д»ҺеҺҹе§Ӣж•°жҚ®дёӯз”ҹжҲҗж”ҫеӨ§ж ·жң¬ гҖӮ 然иҖҢ пјҢ иҝҷдәӣж–№жі•еҸҜиғҪдә§з”ҹдёҺеҺҹе§Ӣж•°жҚ®дёҚеҗҢзҡ„дёҚеҸҜйқ ж ·жң¬ гҖӮ еҸҰдёҖж–№йқў пјҢ дёҖдәӣеӣҫеғҸ DA жҠҖжңҜ[12,42,41]еҜ№е…·жңү规еҲҷз»“жһ„зҡ„еӣҫеғҸеә”з”ЁеғҸзҙ жҸ’еҖј пјҢ дҪҶжҳҜдёҚиғҪеӨ„зҗҶйЎәеәҸдёҚеҸҳзҡ„зӮ№дә‘ гҖӮ еҸҰдёҖз§Қж–№жі•зҡ„зӣ®зҡ„жҳҜжүҫеҲ°дёҖдёӘйў„е…Ҳе®ҡд№үзҡ„иҪ¬жҚўеҮҪж•°зҡ„жңҖдҪіз»„еҗҲ пјҢ д»ҘеўһеҠ и®ӯз»ғж ·жң¬ пјҢ иҖҢдёҚжҳҜеҹәдәҺдәәе·Ҙи®ҫи®ЎжҲ–е®Ңе…ЁйҡҸжңәжҖ§еә”з”ЁиҪ¬жҚўеҮҪж•° гҖӮ
жҺЁиҚҗйҳ…иҜ»










![ж–°еҚҺзҪ‘|еҫ·еӣҪжі•е…°е…ӢзҰҸвҖңи·іиҡӨеёӮеңәвҖқйҮҚж–°ејҖж”ҫ[з»„еӣҫ]](https://mz.eastday.com/16510358.jpeg)





- иҝҗеҠЁи®Ўж•°ејҖеҸ‘йЎ№зӣ®зҡ„еҜ№жҠ—иөӣпјҡйЈһз®—е…ЁиҮӘеҠЁиҪҜ件е·ҘзЁӢе№іеҸ°зўҫеҺӢдј з»ҹжЁЎејҸ
- зү№ж–ҜжӢүйў‘йў‘иҮӘеҠЁеҠ йҖҹгҖҒзӘҒ然еӨұжҺ§пјҹзҫҺеӣҪзӣ‘з®Ўжңәжһ„и°ғжҹҘз»“жһңпјҡиҜҒжҚ®дёҚи¶і
- дёӯзӯ–ж©Ўиғ¶йҰ–еҲӣиғҺйқўеҺӢеҮәдә§зәҝвҖңиҮӘеҠЁй©ҫ驶вҖқпјҢйҮҚйҮҸиҜҜе·®е°ҸдәҺ1%
- ClearbotпјҡдёҖж¬ҫиғҪиҮӘеҠЁеңЁж°ҙдёҠиҝҪиёӘ收йӣҶеһғеңҫзҡ„жңәеҷЁдәә
- LGеҸ‘еёғж–°ж¬ҫж— зәҝеҗёе°ҳеҷЁ еҸҜиҮӘеҠЁжё…з©әйӣҶе°ҳзӣ’
- еҲқжҺў iOS иҮӘеҠЁеҢ–е·Ҙе…·вҖ”вҖ”еҝ«жҚ·жҢҮд»Ө
- жөӢиҜ•|иҮӘеҠЁй©ҫ驶иҪҰиҫҶе°ҶеңЁж·ұеңі19дёӘе…¬ејҖеҢәеҹҹи·ҜжөӢ
- еӣӣз»ҙеӣҫж–°жҗәжүӢе¬ҙеҪ»з§‘жҠҖ й«ҳзІҫеәҰең°еӣҫиҗҪең°иҮӘеҠЁй©ҫ驶干зәҝзү©жөҒ
- йЈһжӯҘж— дәәиҪҰпјҡе®һзҺ°йҰ–дёӘж··зәҝе·ҘеҶөдёӢзҡ„иҮӘеҠЁй©ҫ驶йӣҶеҚЎзј–йҳҹзӢ¬з«Ӣж•ҙиҲ№дҪңдёҡ
- жҲҙе°”еҸ‘еёғLatitude 9000笔记жң¬ж–°е“Ғ жӢҘжңүиҮӘеҠЁж‘„еғҸеӨҙеҝ«й—ЁзӯүеҠҹиғҪ