гҖҢж•°йҮҸжҠҖжңҜе®…пҪңPythonзҲ¬иҷ«зі»еҲ—гҖҚе®һж—¶зӣ‘жҺ§иӮЎеёӮе…¬е‘Ҡзҡ„зҲ¬иҷ«
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
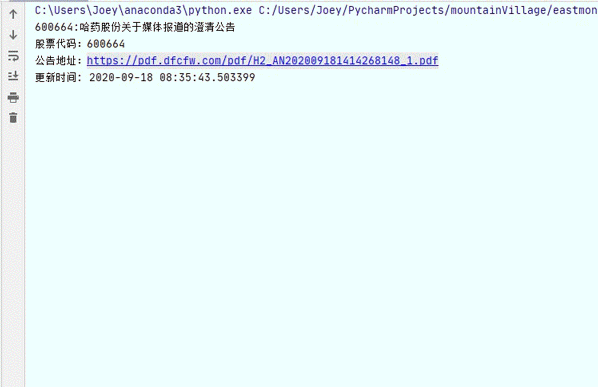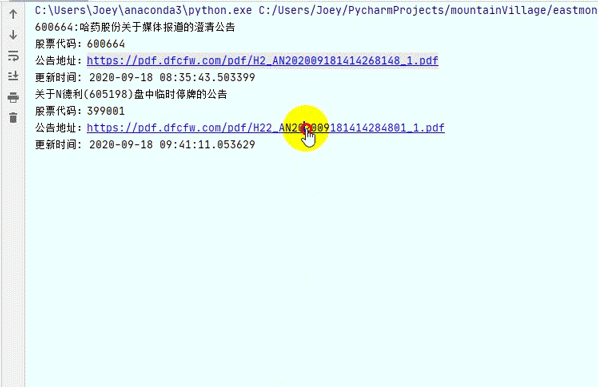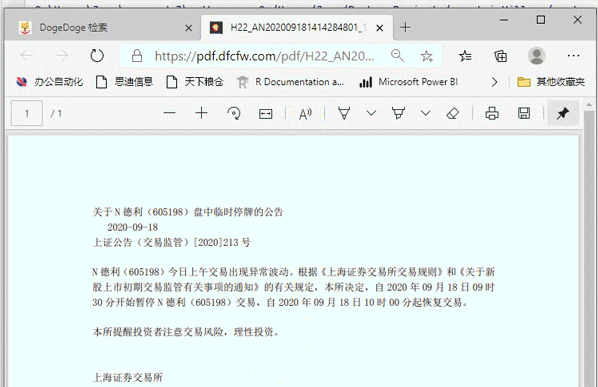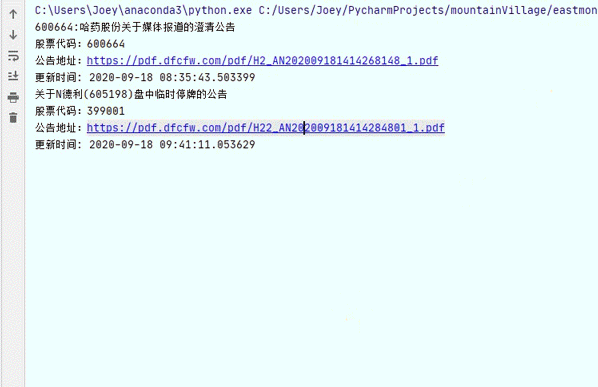
зІҫеҠӣжңүйҷҗзҡ„жҲ‘们 пјҢ еҰӮдҪ•жӣҙеҠ жңүж•ҲзҺҮең°зӣ‘жҺ§дҝЎжҒҜпјҹеҫҲеӨҡж—¶еҖҷзү№еҲ«жҳҜдәӨжҳ“ж—¶ пјҢ жҲ‘们йңҖиҰҒжғіеҠһжі•зӣ‘жҺ§дёҖдәӣдҝЎжҒҜ пјҢ жҜ”еҰӮиӮЎеёӮзҡ„е…¬е‘Ҡ гҖӮ еҰӮжһңзҺ°жңүзҡ„иҪҜ件没жңүеҠһжі•е®һзҺ°жҲ‘们зҡ„йңҖжұӮ пјҢ йӮЈд№Ҳе°ұиҰҒйқ жҲ‘们иҮӘе·ұеҠЁжүӢ пјҢ жүҚиғҪдё°иЎЈи¶ійЈҹ гҖӮ
дҪ еңЁдәӨжҳ“зңӢзӣҳж—¶ пјҢ еҰӮжһңжңүдёҖдёӘе°ҸзӘ—еҸЈ пјҢ е№іж—¶й»ҳй»ҳзҡ„дёҚеЈ°дёҚе“Қ пјҢ дҪҶжҳҜеҰӮжһңжңүе…¬е‘ҠеҸ‘еёғ пјҢ е°ұдјҡжҳҫзӨәе…¬е‘Ҡзҡ„дҝЎжҒҜпјҡиҝҷжҳҜд»Җд№Ҳе…¬е‘Ҡ пјҢ 然еҗҺз»ҷжҲ‘们公е‘Ҡзҡ„й“ҫжҺҘ гҖӮ иҝҷж · пјҢ ж—ўдёҚдјҡеғҸеј№зӘ—йӮЈж ·з”ЁдҝЎжҒҜиҪ°зӮёжҲ‘们 пјҢ еҸҲиғҪеӨҹе®ҡеҲ¶жҲ‘们иҮӘе·ұжғіиҰҒзҡ„еҶ…е®№ пјҢ еҒҡеҲ°жғізңӢе°ұзңӢ пјҢ жғідёҚзңӢе°ұдёҚзңӢ пјҢ йӮЈе°ұеҫҲж–№дҫҝдәҶ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
зҲ¬иҷ«жҠ“еҸ–зҡ„жҳҜдёңж–№иҙўеҜҢдёҠзҡ„дёҠеёӮе…¬еҸёе…¬е‘Ҡ пјҢ дёҠеёӮе…¬еҸёе…¬е‘ҠжңүдәӣдјҡеңЁзӣҳдёӯе…¬еёғ гҖӮ е®һж—¶зӣ‘жҺ§зҡ„еҺҹзҗҶ пјҢ е…¶е®һе°ұжҳҜзЁӢеәҸд»Јжӣҝдәәе·Ҙ пјҢ е®ҡжңҹең°еҺ»еҲ·ж–°зҪ‘йЎө пјҢ 然еҗҺз”ЁеҲ·ж–°еүҚеҗҺеҫ—еҲ°зҡ„ж•°жҚ®иҝӣиЎҢжҜ”еҜ№ пјҢ еҰӮжһңдёҖж · пјҢ йӮЈд№Ҳзӯүеҫ…дёӢдёҖдёӘе‘Ёжңҹ继з»ӯеҲ·ж–° пјҢ еҰӮжһңдёҚдёҖж · пјҢ йӮЈд№Ҳе°ұжҠҠеўһйҮҸдҝЎжҒҜжҸҗеҸ–еҮәжқҘ пјҢ дҫӣжҲ‘们жҹҘйҳ… гҖӮ
еҲ©з”ЁpythonзҲ¬иҷ«е®һж—¶зӣ‘жҺ§е…¬е‘ҠдҝЎжҒҜеӣӣйғЁжӣІз¬¬дёҖжӯҘ пјҢ еҜје…ҘйҡҸжңәиҜ·жұӮеӨҙе’ҢйңҖиҰҒзҡ„еҢ…
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
жҲ‘们дҪҝз”ЁjsonжқҘи§ЈжһҗиҺ·еҸ–зҡ„дҝЎжҒҜ пјҢ дҪҝз”Ёд»Җд№Ҳж–№жі•и§Јжһҗж•°жҚ®еҸ–еҶідәҺжҲ‘们иҜ·жұӮж•°жҚ®зҡ„иҝ”еӣһеҪўејҸ пјҢ иҝҷйҮҢдҪҝз”ЁjsonжңҖж–№дҫҝ пјҢ жҲ‘们е°ұеҜје…ҘjsonеҢ… гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
第дәҢжӯҘ пјҢ иҺ·еҸ–еҲқе§Ӣзҡ„е…¬е‘Ҡж•°жҚ®
жҲ‘们еҸ‘зҺ° пјҢ жҜҸдёҖдёӘе…¬е‘ҠйғҪжңүдёҖдёӘзӢ¬жңүзҡ„ж–Үз« еҸ·з Ғпјҡart_code пјҢ еӣ жӯӨжҲ‘们д»ҘиҝҷдёӘеҸ·з ҒдҪңдёәж–°ж—§жҜ”иҫғзҡ„еҹәеҮҶ пјҢ еҰӮжһңж–°йЎөйқўзҡ„еӨҙдёҖдёӘе…¬е‘Ҡзҡ„art_codeе’Ңе·Іжңүзҡ„дёҖиҮҙ пјҢ йӮЈд№Ҳе°ұиҝӣе…ҘдёӢдёҖдёӘеҲ·ж–°е‘Ёжңҹ пјҢ еҰӮжһңдёҚдёҖиҮҙ пјҢ йӮЈд№ҲиҜҙжҳҺйЎөйқўе·Із»Ҹжӣҙж–°иҝҮдәҶ пјҢ жҲ‘们жҸҗеҸ–жңҖж–°зҡ„жҠҘе‘Ҡ пјҢ еҗҢж—¶жӣҙж–°иҝҷдёӘart_code пјҢ з”ЁдәҺдёӢдёҖж¬ЎжҜ”еҜ№ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
- еҺҹе§Ӣurlзҡ„иҺ·еҸ– гҖӮ иҺ·еҸ–д№ӢеҗҺ пјҢ йҖҡиҝҮjsonи§Јжһҗе…¶дёӯзҡ„еҶ…е®№ пјҢ еҫ—еҲ°art_code пјҢ иҰҶзӣ–еҶҷе…ҘеңЁtmp.txtж–Ү件дёӯ пјҢ з”ЁдәҺжҜ”еҜ№ гҖӮ
- иҜ»еҸ–дәҶtmp.txtж–Ү件дёӯзҡ„art_code пјҢ и·ҹйЎөйқўи§Јжһҗзҡ„art_codeжҜ”еҜ№ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ第дёүжӯҘ пјҢ иҺ·еҸ–е…¬е‘Ҡж Үйўҳе’Ңж–Үз« й“ҫжҺҘ
- йҖҡиҝҮjsonжҲ‘们еҹәжң¬дёҠе·Із»ҸиғҪеӨҹи§ЈжһҗеҮәеӨ§йғЁеҲҶзҡ„ж•°жҚ®еҶ…е®№ гҖӮ
- йҖҡиҝҮи§ӮеҜҹзҪ‘з«ҷзҡ„е…¬е‘Ҡй“ҫжҺҘзҡ„зү№зӮ№ пјҢ жҲ‘们еҸ‘зҺ°дё»иҰҒзҡ„е·®еҲ«е°ұжҳҜеңЁart_code пјҢ еӣ жӯӨйҖҡиҝҮзҪ‘еқҖй“ҫжҺҘзҡ„жӢјжҺҘ пјҢ жҲ‘们е°ұиғҪеӨҹеҫ—еҲ°е…¬е‘Ҡзҡ„pdfй“ҫжҺҘ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ第еӣӣжӯҘ пјҢ иҝҗиЎҢжҲ‘们зҡ„зЁӢеәҸ
зЁӢеәҸиҝҗиЎҢзҡ„з»“жһңдјҡжү“еҚ°еҲ°зӘ—еҸЈеҪ“дёӯ пјҢ жҜҸеҪ“жңүж–°зҡ„е…¬е‘ҠеҸ‘еёғ пјҢ зЁӢеәҸдёҠе°ұдјҡеҮәзҺ°дёҖдёІж–°зҡ„дҝЎжҒҜ гҖӮ
жңҖеҗҺиҮӘжӯӨ пјҢ жҲ‘们йҖҡиҝҮзЁӢеәҸжҠҠжҲ‘们иҰҒзҡ„дҝЎжҒҜжү“еҚ°еҲ°дәҶзЁӢеәҸзҡ„иҝҗиЎҢзӘ—еҸЈ пјҢ еҗҢж—¶ пјҢ жҲ‘们зҡ„зЁӢеәҸд№ҹеҸҜд»Ҙж №жҚ®жҲ‘们йңҖжұӮиҝӣиЎҢејәеҢ–е’Ңжү©е…… гҖӮ йҰ–е…Ҳ пјҢ иҝҷдәӣдҝЎжҒҜд№ҹеҸҜд»Ҙйқһеёёж–№дҫҝзҡ„йҖҡиҝҮжҺҘеҸЈеҸ‘йҖҒеҲ°йӮ®з®ұгҖҒй’үй’үзӯүе№іеҸ° пјҢ иө·еҲ°е®һж—¶жҸҗйҶ’зҡ„дҪңз”Ё пјҢ е…¶ж¬Ў пјҢ жҲ‘们д№ҹеҸҜд»Ҙд»ҺдёҚеҗҢзҡ„ең°ж–№жҠ“еҸ–дҝЎжҒҜ пјҢ е®ҢжҲҗжүҖйңҖдҝЎжҒҜзҡ„иҮӘе®ҡд№үж•ҙеҗҲ пјҢ иҝҷдәӣе°ҶеңЁжҲ‘们еҗҺз»ӯзҡ„ж–Үз« дёӯжҸҗеҲ° гҖӮ
ж–Үз« е’Ңд»Јз Ғд»…дҫӣдәӨжөҒеӯҰд№ пјҢ иҜ·еӢҝз”ЁдәҺйқһжі•з”ЁйҖ” гҖӮ
гҖҗгҖҢж•°йҮҸжҠҖжңҜе®…пҪңPythonзҲ¬иҷ«зі»еҲ—гҖҚе®һж—¶зӣ‘жҺ§иӮЎеёӮе…¬е‘Ҡзҡ„зҲ¬иҷ«гҖ‘гҖҢж•°йҮҸжҠҖжңҜе®…пҪңPythonзҲ¬иҷ«зі»еҲ—гҖҚзҺ°иҙ§еӯЈиҠӮжҖ§и·ҹиёӘзҡ„зҲ¬иҷ«еҲҶдә«
жҺЁиҚҗйҳ…иҜ»


















- жҗӯиҪҪеӨ©зҺ‘1000+ иҚЈиҖҖV40жқҘдәҶпјҒиөөжҳҺпјҡдёҖеҰӮж—ўеҫҖеқҡжҢҒжҠҖжңҜеҲӣж–°
- и®Ўз®—жңәдё“дёҡеӨ§дёҖдёӢеӯҰжңҹпјҢиҜҘйҖүжӢ©еӯҰд№ JavaиҝҳжҳҜPython
- TikTokжҺЁеҮәйҰ–дёӘеҲ©з”ЁiPhone 12 Pro LiDARжҠҖжңҜзҡ„ARзү№ж•Ҳ
- Looking GlassжҺЁеҮәз”ұе…ЁжҒҜжҲҗеғҸжҠҖжңҜжү“йҖ зҡ„3Dз…§зүҮиҪҜ件
- жңҖеЈ•вҖңе№ҙз»ҲеҘ–вҖқеҮәзӮүпјҒйӣ·еҶӣдёӢиЎҖжң¬пјҡдёҖж¬ЎйўҒеҸ‘дёӨдёӘзҷҫдёҮзҫҺйҮ‘жҠҖжңҜеӨ§еҘ–
- е°ҸзұіжҺҲдәҲжҠҖжңҜеӣўйҳҹзҷҫдёҮзҫҺе…ғеӨ§еҘ– йӣ·еҶӣпјҡе°Ҷ继з»ӯеҠ еӨ§жҠҖжңҜжҠ•е…Ҙ
- гҖҢеӨ®е№ҝзҪ‘иҜ„гҖҚжү«з ҒзӮ№йӨҗ жҠҖжңҜиҝӣжӯҘдёҚиғҪи„ұзҰ»дәәжҖ§еҢ–жңҚеҠЎ
- еҚҺдёәдёәжІіеҢ—вҖңзҒ«зңјвҖқе®һйӘҢе®ӨпјҲж°”иҶңзүҲпјүжҸҗдҫӣзҪ‘з»ңжҠҖжңҜдҝқйҡң
- дёҺиҚ·е…°е…үеҲ»жңәе®ҢжҲҗиҒ”жңәпјҒеӣҪдә§иҠҜзүҮи®ҫеӨҮдј жқҘе–ңи®ҜпјҡжҠҖжңҜй—®йўҳе·Із»Ҹи§ЈеҶі
- жғіиҮӘеӯҰPythonжқҘејҖеҸ‘зҲ¬иҷ«пјҢйңҖиҰҒжҢүз…§е“ӘеҮ дёӘйҳ¶ж®өеҲ¶е®ҡеӯҰд№ и®ЎеҲ’