дҪҝз”ЁCatBoostе’ҢNODEе»әжЁЎиЎЁж јж•°жҚ®еҜ№жҜ”жөӢиҜ•
жқҘиҮӘдҝ„зҪ—ж–ҜеңЁзәҝжҗңзҙўе…¬еҸёYandexзҡ„CatBoostеҝ«йҖҹдё”жҳ“дәҺдҪҝз”Ё пјҢ дҪҶеҗҢдёҖ家公еҸёзҡ„з ”з©¶дәәе‘ҳжңҖиҝ‘еҸ‘еёғдәҶдёҖз§ҚеҹәдәҺзҘһз»ҸзҪ‘з»ңзҡ„ж–°иҪҜ件еҢ…NODE пјҢ еЈ°з§°е…¶жҖ§иғҪдјҳдәҺCatBoostе’ҢжүҖжңүе…¶д»–жўҜеәҰеўһејәж–№жі• гҖӮиҝҷжҳҜзңҹзҡ„еҗ—пјҹ и®©жҲ‘们жүҫеҮәеҰӮдҪ•еҗҢж—¶дҪҝз”ЁCatBoostе’ҢNODEпјҒ
иҜҘж–Үз« йҖӮз”ЁдәҺи°Ғпјҹе°Ҫз®ЎжҲ‘жҳҜдёәйӮЈдәӣеҜ№жңәеҷЁеӯҰд№ зү№еҲ«жҳҜиЎЁж јж•°жҚ®ж„ҹе…ҙи¶Јзҡ„дәәеҶҷиҝҷзҜҮеҚҡе®ўзҡ„ пјҢ дҪҶжҳҜеҰӮжһңжӮЁзҶҹжӮүPythonе’Ңscikit-learnеә“ пјҢ 并且еёҢжңӣи·ҹйҡҸд»Јз ҒдёҖиө·еӯҰд№ пјҢ еҜ№жӮЁеҫҲжңүеё®еҠ© гҖӮеҗҰеҲҷ пјҢ еёҢжңӣжӮЁдјҡеҸ‘зҺ°зҗҶи®әе’ҢжҰӮеҝөж–№йқўйғҪеҫҲжңүи¶ЈпјҒ
CatBoostз®Җд»ӢCatBoostжҳҜжҲ‘е»әжЁЎиЎЁж јж•°жҚ®зҡ„йҰ–йҖүеҢ… гҖӮ иҝҷжҳҜдёҖдёӘжўҜеәҰеўһејәеҶізӯ–ж ‘зҡ„е®һзҺ° пјҢ еҸӘжҳҜеҒҡдәҶдёҖдәӣеҫ®и°ғ пјҢ дҪҝе…¶дёҺдҫӢеҰӮxgboostжҲ–LightGBMз•ҘжңүдёҚеҗҢ гҖӮ е®ғеҜ№еҲҶзұ»е’ҢеӣһеҪ’й—®йўҳйғҪжңүж•Ҳ гҖӮ
е…ідәҺCatBoostзҡ„дёҖдәӣеҘҪеӨ„:
В· е®ғеӨ„зҗҶеҲҶзұ»зү№еҫҒ(иҷҪ然дёҚжҳҜжңҖдјҳи§Ј) пјҢ жүҖд»ҘдҪ дёҚйңҖиҰҒжӢ…еҝғеҰӮдҪ•зј–з Ғе®ғ们 гҖӮ
В· е®ғйҖҡеёёеҸӘйңҖиҰҒеҫҲе°‘зҡ„еҸӮж•°и°ғдјҳ гҖӮ
В· е®ғйҒҝе…ҚдәҶе…¶д»–ж–№жі•еҸҜиғҪйҒӯеҸ—зҡ„жҹҗдәӣеҫ®еҰҷзұ»еһӢзҡ„ж•°жҚ®жі„жјҸ гҖӮ
В· е®ғйҖҹеәҰеҫҲеҝ« пјҢ еҰӮжһңдҪ жғіи®©е®ғи·‘еҫ—жӣҙеҝ« пјҢ еҸҜд»ҘеңЁGPUдёҠиҝҗиЎҢ гҖӮ
иҝҷдәӣеӣ зҙ дҪҝеҫ—CatBoostеҜ№жҲ‘жқҘиҜҙ пјҢ еҪ“жҲ‘йңҖиҰҒеҲҶжһҗдёҖдёӘж–°зҡ„иЎЁж јж•°жҚ®йӣҶж—¶ пјҢ йҰ–е…ҲиҰҒеҒҡзҡ„е°ұжҳҜдҪҝз”Ёе®ғ гҖӮ
CatBoostзҡ„жҠҖжңҜз»ҶиҠӮеҰӮжһңдҪ еҸӘжҳҜжғідҪҝз”ЁCatBoost пјҢ иҜ·и·іиҝҮиҝҷдёҖиҠӮ!
еңЁжӣҙжҠҖжңҜзҡ„еұӮйқўдёҠ пјҢ е…ідәҺCatBoostзҡ„е®һзҺ°жңүдёҖдәӣжңүи¶Јзҡ„дәӢжғ… гҖӮ еҰӮжһңжӮЁеҜ№з»ҶиҠӮж„ҹе…ҙи¶Ј пјҢ жҲ‘ејәзғҲжҺЁиҚҗи®әж–ҮCatboost: unbiased boosting with categorical features гҖӮ жҲ‘еҸӘжғіејәи°ғдёӨ件дәӢ гҖӮ
еңЁи®әж–Үдёӯ пјҢ дҪңиҖ…жҢҮеҮә пјҢ ж ҮеҮҶзҡ„жўҜеәҰеўһејәз®—жі•дјҡеҸ—еҲ°дёҖдәӣеҫ®еҰҷзҡ„ж•°жҚ®жі„жјҸзҡ„еҪұе“Қ пјҢ иҝҷдәӣжі„жјҸжҳҜз”ұжЁЎеһӢзҡ„иҝӯд»ЈжӢҹеҗҲж–№ејҸеј•иө·зҡ„ гҖӮ еҗҢж · пјҢ жңҖжңүж•Ҳзҡ„еҜ№еҲҶзұ»зү№еҫҒиҝӣиЎҢж•°еӯ—зј–з Ғзҡ„ж–№жі•(еҰӮзӣ®ж Үзј–з Ғ)д№ҹе®№жҳ“еҮәзҺ°ж•°жҚ®жі„жјҸе’ҢиҝҮжӢҹеҗҲ гҖӮ дёәдәҶйҒҝе…Қиҝҷз§Қжі„жјҸ пјҢ CatBoostеј•е…ҘдәҶдёҖдёӘдәәе·Ҙж—¶й—ҙиҪҙ пјҢ ж №жҚ®и®ӯз»ғзӨәдҫӢеҲ°иҫҫзҡ„ж—¶й—ҙиҪҙ пјҢ иҝҷж ·еңЁи®Ўз®—з»ҹи®Ўж•°жҚ®ж—¶еҸӘиғҪдҪҝз”Ё"д»ҘеүҚзңӢеҲ°зҡ„"зӨәдҫӢ гҖӮ
CatBoostе®һйҷ…дёҠ并дёҚдҪҝ用常规еҶізӯ–ж ‘ пјҢ иҖҢжҳҜдҪҝз”ЁйҒ—еҝҳзҡ„еҶізӯ–ж ‘ гҖӮ еңЁиҝҷдәӣж ‘дёӯ пјҢ еңЁж ‘зҡ„жҜҸдёҖеұӮдёҠ пјҢ зӣёеҗҢзҡ„зү№жҖ§е’ҢзӣёеҗҢзҡ„еҲҶеүІж ҮеҮҶиў«еҲ°еӨ„дҪҝз”Ё!иҝҷеҗ¬иө·жқҘеҫҲеҘҮжҖӘ пјҢ дҪҶжңүдёҖдәӣдёҚй”ҷзҡ„еұһжҖ§ гҖӮ и®©жҲ‘们зңӢзңӢиҝҷжҳҜд»Җд№Ҳж„ҸжҖқ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
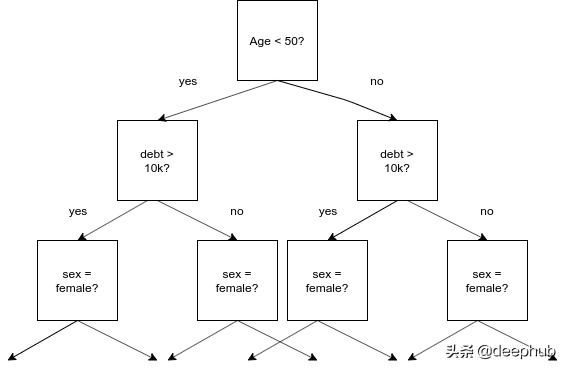
йҒ—еҝҳзҡ„еҶізӯ–ж ‘ гҖӮжҜҸдёӘзә§еҲ«йғҪжңүзӣёеҗҢзҡ„жӢҶеҲҶ гҖӮ
 ж–Үз« жҸ’еӣҫ
ж–Үз« жҸ’еӣҫ
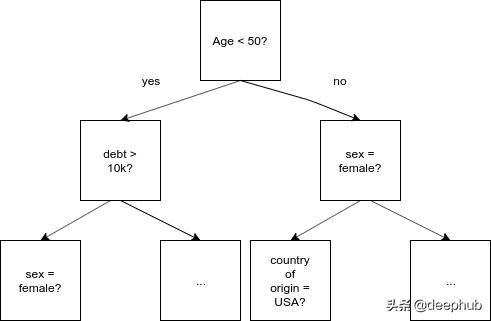
常规еҶізӯ–ж ‘ гҖӮжҜҸдёӘзә§еҲ«дёҠйғҪеҸҜд»ҘеӯҳеңЁд»»дҪ•еҠҹиғҪжҲ–еҲҶеүІзӮ№ гҖӮ
еңЁжҷ®йҖҡзҡ„еҶізӯ–ж ‘дёӯ пјҢ иҰҒеҲҶеүІзҡ„зү№жҖ§е’ҢжҲӘжӯўеҖјйғҪеҸ–еҶідәҺеҲ°зӣ®еүҚдёәжӯўеңЁж ‘дёӯжүҖиө°зҡ„и·Ҝеҫ„ гҖӮ иҝҷжҳҜжңүж„Ҹд№үзҡ„ пјҢ еӣ дёәжҲ‘们еҸҜд»ҘдҪҝз”ЁжҲ‘们已з»ҸжӢҘжңүзҡ„дҝЎжҒҜжқҘеҶіе®ҡжңҖжңүж„Ҹд№үзҡ„дёӢдёҖдёӘй—®йўҳ гҖӮ жңүдәҶеҒҘеҝҳеҶізӯ–ж ‘ пјҢ еҺҶеҸІе°ұдёҚйҮҚиҰҒдәҶ;жҲ‘д»¬ж— и®әеҰӮдҪ•йғҪиҰҒжҸҗеҮәеҗҢж ·зҡ„й—®йўҳ гҖӮ иҝҷдәӣж ‘иў«з§°дёә"еҒҘеҝҳзҡ„" пјҢ еӣ дёәе®ғ们жҖ»жҳҜ"еҝҳи®°"еҸ‘з”ҹиҝҮзҡ„дәӢжғ… гҖӮ
дёәд»Җд№ҲиҝҷдёӘжңүз”Ё?еҒҘеҝҳеҶізӯ–ж ‘зҡ„дёҖдёӘеҫҲеҘҪзҡ„зү№жҖ§жҳҜ пјҢ дёҖдёӘдҫӢеӯҗеҸҜд»Ҙйқһеёёеҝ«йҖҹең°еҲҶзұ»жҲ–еҫ—еҲҶвҖ”вҖ”е®ғжҖ»жҳҜжҸҗеҮәзӣёеҗҢзҡ„NдёӘдәҢеҸүй—®йўҳ(е…¶дёӯNжҳҜж ‘зҡ„ж·ұеәҰ) гҖӮ еҜ№дәҺи®ёеӨҡдҫӢеӯҗжқҘиҜҙ пјҢ иҝҷеҸҜд»ҘеҫҲе®№жҳ“ең°е№¶иЎҢе®ҢжҲҗ гҖӮ иҝҷжҳҜCatBoostеҝ«йҖҹеҸ‘еұ•зҡ„еҺҹеӣ д№ӢдёҖ гҖӮ еҸҰдёҖ件иҰҒи®°дҪҸзҡ„дәӢжғ…жҳҜжҲ‘们иҝҷйҮҢеӨ„зҗҶзҡ„жҳҜдёҖдёӘж ‘йӣҶеҗҲ гҖӮ дҪңдёәдёҖз§ҚзӢ¬з«Ӣзҡ„з®—жі• пјҢ еҒҘеҝҳеҶізӯ–ж ‘еҸҜиғҪжІЎжңүйӮЈд№ҲеҘҪ пјҢ дҪҶж ‘йӣҶеҗҲзҡ„жҖқжғіжҳҜ пјҢ з”ұдәҺй”ҷиҜҜе’ҢеҒҸи§Ғиў«"жҙ—жҺү" пјҢ дёҖдёӘејұеӯҰд№ иҖ…зҡ„иҒ”зӣҹз»Ҹеёёе·ҘдҪңеҫ—еҫҲеҘҪ гҖӮ йҖҡеёёжғ…еҶөдёӢ пјҢ ејұеӯҰд№ иҖ…жҳҜдёҖжЈөж ҮеҮҶзҡ„еҶізӯ–ж ‘ пјҢ иҖҢеңЁиҝҷйҮҢ пјҢ е®ғз”ҡиҮіжӣҙејұ пјҢ д№ҹе°ұжҳҜеҒҘеҝҳеҶізӯ–ж ‘ гҖӮ CatBoostзҡ„дҪңиҖ…и®Өдёә пјҢ иҝҷз§Қзү№ж®Ҡзҡ„ејұеӯҰд№ иҖ…еңЁжіӣеҢ–ж–№йқўе·ҘдҪңеҫ—еҫҲеҘҪ гҖӮ
е®үиЈ…CatBoostе®үиЈ…CatBoostжҳҜйқһеёёз®ҖеҚ•зҡ„
pip install catboost
жҲ‘еңЁMacдёҠжңүж—¶дјҡйҒҮеҲ°иҝҷж ·зҡ„й—®йўҳ гҖӮ еңЁLinuxзі»з»ҹдёҠ пјҢ жҜ”еҰӮжҲ‘зҺ°еңЁиҫ“е…Ҙзҡ„Ubuntuзі»з»ҹ пјҢ жҲ–иҖ…еңЁи°·жӯҢColaboratoryдёҠ пјҢ е®ғеә”иҜҘ"жӯЈеёёе·ҘдҪң" гҖӮ еҰӮжһңе®үиЈ…ж—¶дёҖзӣҙжңүй—®йўҳ пјҢ еҸҜд»ҘиҖғиҷ‘дҪҝз”ЁDockerй•ңеғҸ гҖӮ
жҺЁиҚҗйҳ…иҜ»












![дәәж°‘зҪ‘|[зҪ‘иҝһдёӯеӣҪ]д№Ўйҹіе”ұж–°йЈҺгҖҒе®ҡзәҰйҷӨйҷӢд№ пјҢж–ҮжҳҺе®һи·өжңҖеҗҺ"дёҖе…¬йҮҢ"йҖҡдәҶ](https://mz.eastday.com/18403767.jpg)






- Biogenе°ҶдҪҝз”ЁApple Watchз ”з©¶иҖҒе№ҙз—ҙе‘Ҷз—Үзҡ„ж—©жңҹз—ҮзҠ¶
- Eyeware BeamдҪҝз”ЁiPhoneиҝҪиёӘзҺ©е®¶еңЁжёёжҲҸдёӯзҡ„зңјзқӣиҝҗеҠЁ
- жҲ–дҪҝз”ЁеӨ©зҺ‘1000+иҠҜзүҮпјҹиҚЈиҖҖV40е·Іе…Ёжё йҒ“ејҖеҗҜйў„зәҰ
- иӢ№жһңе°ҶжҺЁеҮәдҪҝз”Ёmini LEDеұҸзҡ„iPad Pro
- жүӢжңәиғҪз”ЁеӨҡд№…пјҹеҰӮжһңеҮәзҺ°иҝҷ3з§ҚеҫҒе…ҶпјҢиҜҙжҳҺвҖңй»ҳи®ӨдҪҝз”Ёж—¶й—ҙвҖқе·ІеҲ°
- иӢ№жһңжңүжңӣеңЁ2021е№ҙеҲқеҸ‘еёғйҰ–ж¬ҫдҪҝз”Ёmini LEDжҳҫзӨәеұҸзҡ„ iPad Pro
- 笔记жң¬дҝқе…»жңүеҰҷжӢӣпјҒеӯҰдјҡиҝҷеҮ жӢӣ笔记жң¬еҶҚжҲҳдёүе№ҙ
- ж•°жҚ®еҸҜи§ҶеҢ–дёүиҠӮиҜҫд№ӢдәҢпјҡеҸҜи§ҶеҢ–зҡ„дҪҝз”Ё
- зҙўе°јsw77дёҺsw55зҡ„дҪҝз”Ёе·®еҲ«ж„ҹеҸ—
- зҲҶж–ҷз§°дёҖеҠ 9зі»еҲ—дёҺжҪңжңӣејҸй•ңеӨҙж— зјҳ 继з»ӯдҪҝз”Ёжҷ®йҖҡй•ҝз„Ұ