训练|零代码、自动化、定制训练文字识别 百度EasyDL全新发布OCR自训练平台
_原题为 零代码、自动化、定制训练文字识别 百度EasyDL全新发布OCR自训练平台
OCR(文字识别)技术是最早应用于企业降本增效的 AI 方向之一 , 如今已逐渐下沉为企业智能化升级的一项重要基础设施能力 。 10月29日 , 百度智能云线上线下同期举办了TechDay OCR技术创新沙龙 , 深度分享OCR产品矩阵、功能、应用案例等最新进展 , 并重磅全新发布EasyDL OCR自训练平台 。 泰康保险集团、北京融汇金信等企业伙伴在现场分享了OCR在企业内的应用经验和心得 。 百度智能云OCR产品为企业打造了技术领先、类型丰富同时支持便捷自定制的解决方案 , 已广泛应用于金融服务、财税报销、快递物流、法律政务、交通出行、教育培训、内容审核等全行业领域 , 加快推动企业实现产业智能化升级 。
业界首发EasyDL OCR自训练平台 , 低成本满足OCR定制化需求
近年来 , OCR的识别能力不断突破 , 逐渐在更加复杂的数字化场景发挥作用 , 有效降低信息提取和录入的人力成本 , 帮助企业专注于上层业务应用 。 与此同时 , 企业对于OCR识别模型定制化的需求日益旺盛 , 包括OCR在特定场景下是否有高精度识别效果、能否高效响应自身业务需求、是否能在模型训练过程中保证数据安全 , 以上三点成为行业共性诉求 。
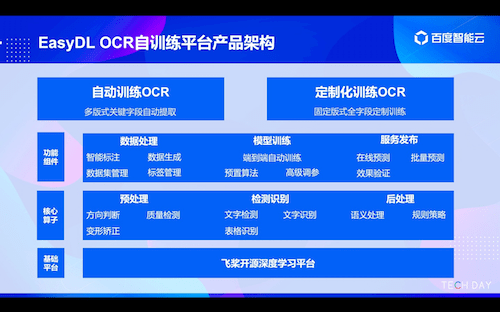
为满足企业快速定制OCR识别模型的诉求 , EasyDL OCR自训练平台应运而生 。 据介绍 , EasyDL OCR 自训练平台具有两大核心产品功能 , 即自动训练OCR和定制化训练OCR;同时具备三大产品特性 , 包括内置成熟OCR技术方案 , 预置经过真实业务检验的多种自动化机制 , 如智能标注、自动数据预处理、虚拟数据生成等 , 同时还开放了调参能力 , 满足多种场景OCR模型定制训练需求 , 保证高准确率;可视化模型训练 , 预置领先的OCR算法 , 可实现零门槛模型训练 , 高效响应业务需求;支持本地私有化部署 , 数据无需出厂 , 有效保障数据安全 。
文章图片
会上 , EasyDL OCR产品负责人还分别演示了自动化训练OCR和定制化训练OCR模型训练过程 , 并在最后总结了适合应用的不同场景和优势 。
具体而言 , 自动化训练OCR每个版式仅需1张训练图片 , “智能标注”功能支持快速标注关键字段 , 显著提升标注效率 , 系统自动完成模板分类 , 可应用于版式多样、识别特定字段、图像质量统一的场景 , 同时模型重训功能支持新增版式的快速扩充 。 定制化训练OCR则具有数据自动生成能力 , 可模拟各类真实场景中复杂数据状况 , 如模糊、变形、缺角等 , 少量标注数据即可获得更高的识别准确率 , 可应用于版式固定、全字段识别、图片质量复杂的场景 。
百度OCR“技术+产品+应用”行业领先 , 助力企业智能化升级
百度OCR是国内应用最广泛的文字识别服务 , 依托业界领先的深度学习技术和海量优质数据 , 提供多场景、多语种、高精度的文字检测与识别服务 , 并针对图片模糊、倾斜、翻转等情况进行深度优化 , 鲁棒性强 , 多项ICDAR指标居世界第一 , 通用、主流卡证识别准确率高达99% 。
而其背后正是由百度AI核心技术引擎——百度大脑支撑 , 如今升级到6.0的百度大脑已成为AI新型基础设施 。 从基础层的算力、数据、飞桨深度学习平台 , 到感知层的语音、视觉、AR/VR , 再到认知层的语言与知识 , 以及平台层的AI平台与生态 , 百度大脑始终保持核心技术持续领先 , 不断夯实“软硬一体AI大生产平台” , 并通过百度智能云整合输出产品服务 , 加速产业智能转型升级 。 截至目前 , 百度大脑已经开放了273项AI能力 , 凝聚超过230万开发者 , 培养了超过100万AI人才 , 在众多行业领域落地应用 , 推动了中国AI技术研发、实践应用与生态建设 。
【训练|零代码、自动化、定制训练文字识别 百度EasyDL全新发布OCR自训练平台】产业智能化升级一个核心前提就是 , 信息数字化和结构化 。 OCR作为最早应用于企业效率提升的AI方向之一 , 显著提升了信息提取和录入的效率 , 实现了信息处理的“电子化”、“自动化” , 为上层业务应用提供有力支撑 。
据现场介绍 , 百度OCR技术经过多年沉淀和实践打磨 , 在多项行业竞赛评比当中持续摘得桂冠 。 例如:2019年从90多支参赛队伍中脱颖而出 , 获得中国最高等级商业领域人工智能技术竞赛唯一A级别证书;在OCR领域最具影响力的ICDAR 19 MLT (多语种task)榜单当中获得文字检测领域世界冠军; 。 同时 , 百度OCR也在不断推进算法创新和突破 , 引领行业技术发展 , 例如:发布了业界最大的中文OCR数据集 , 首次提出端到端OCR-部分监督算法End2End-PSL , 实现精标数据+弱标数据的混合训练 , 克服精标数据成本高问题 , 使得标注成本降低至1/90 。
依托百度大脑领先的深度学习技术 , 百度OCR已开放全系列50多款产品 , 不仅可以实现通用场景的文字识别 , 还可满足各类垂直场景的信息电子化、结构化识别需求 , 例如财务票据识别、医疗票据识别、教育场景的公式识别和试卷识别等等 。
推荐阅读








![[走私]警方突袭走私仓库,发现10架共轴旋翼直升机,居然是纯手工打造](http://img88.010lm.com/img.php?https://image.uc.cn/s/wemedia/s/2020/c8ccb32baca45ed2b7fdedb939dbab14.jpg)




![[辅助训练]分清主次,辅助训练只能是辅助!](http://ttbs.guangsuss.com/image/a9e56a600a9c6f896d0b8d5345ff816b)


- 崔宝秋|对话小米崔宝秋:“宁愿写代码,不愿做PPT”的工程师是技术之根
- 案例|实在智能丨RPA如何实现财务的自动化?5个案例告诉你
- 瑞克|用GPT-2做个“姥爷”!57行代码给《瑞克和莫蒂》写新剧集
- 昆明|交1万元训练考满分?昆明现体育中考培训班
- 小编|又一小鲜肉综艺来袭,集结五位音痴进行训练:没有刘昊然我不看
- 水貂|丹麦杀死的貂将被埋在军事训练区
- 自动化|【安永大咖在进博】数字化科技赋能未来税务转型
- 博瑞|博瑞智2020年中学生潜能训练营最新课程安排表
- 经验教程|博瑞智2020年 小学生潜能训练营最新课程安排表
- 企业|实在智能丨什么是机器人流程自动化RPA?