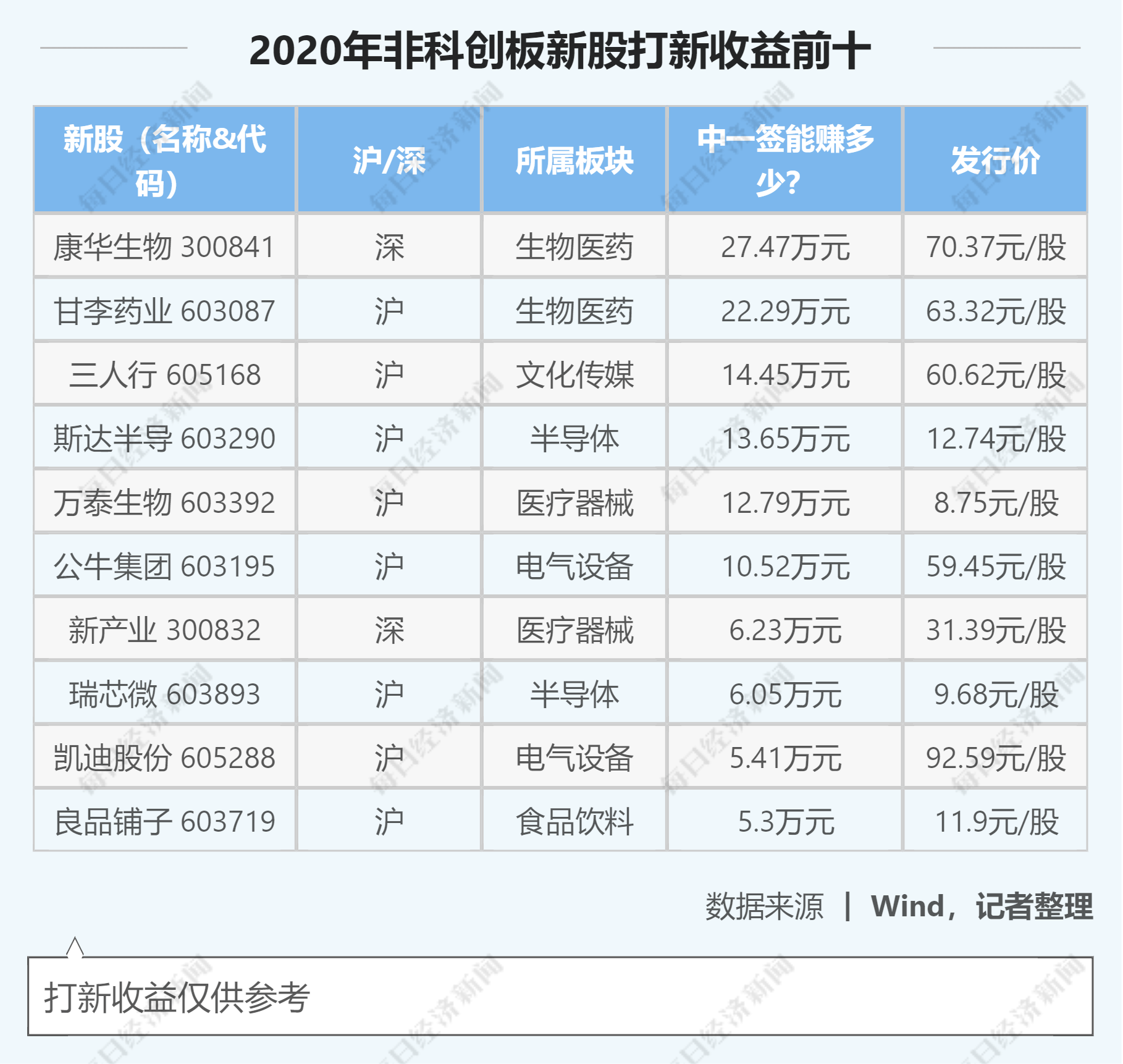
|жҠӣејғжіЁж„ҸеҠӣпјҢзұ»Transformerж–°жЁЎеһӢе®һзҺ°ж–°SOTA( дёү )
жң¬ж–ҮжҸ’еӣҫ
еҲ©з”ЁеӨҡжҹҘиҜў lambda йҷҚдҪҺеӨҚжқӮеәҰ
еҜ№дәҺеӨҡдёӘ |b| е…ғзҙ пјҢ жҜҸдёӘйғҪеҢ…еҗ« |n| иҫ“е…Ҙ гҖӮ еә”з”Ё lambda еұӮжүҖйңҖз®—ж•°иҝҗз®—е’ҢеҶ…еӯҳеҚ з”Ёзҡ„ж•°йҮҸеҲҶеҲ«дёә Оҳ(bnmkv) е’Ң Оҳ(bnkv + knm) гҖӮ з”ұдәҺE_nm еҸӮж•°жҚ•иҺ·дәҶеҹәдәҺдҪҚзҪ®зҡ„дәӨдә’пјҢ еӣ жӯӨзӣёеҜ№дәҺиҫ“е…Ҙй•ҝеәҰ пјҢ з ”з©¶иҖ…жӢҘжңүзҡ„еҶ…еӯҳеҚ з”Ёд»ҚжҳҜдәҢж¬Ўзҡ„ гҖӮ дҪҶжҳҜ пјҢ иҝҷдёӘдәҢ次项并дёҚйҡҸжү№еӨ§е°Ҹжү©еұ• пјҢ иҝҷдёҺз”ҹжҲҗжҜҸдёӘзӨәдҫӢпјҲper-exampleпјүжіЁж„ҸеҠӣеӣҫи°ұзҡ„жіЁж„ҸеҠӣж“ҚдҪңдёҖж · гҖӮ еңЁе®һи·өдёӯ пјҢ и¶…еҸӮж•° |k| и®ҫдёәеҫҲе°Ҹзҡ„еҖј пјҢ еҰӮ |k| =16 пјҢ 并且еңЁжіЁж„ҸеҠӣеӨұж•Ҳзҡ„жғ…еҶөдёӢеҸҜд»ҘеӨ„зҗҶеӨ§жү№йҮҸзҡ„еӨ§еһӢиҫ“е…Ҙ гҖӮ
еӨҡжҹҘиҜў lambdas еҸҜд»ҘйҷҚдҪҺеӨҚжқӮеәҰ гҖӮ lambdas е°ҶжіЁж„ҸеҠӣеӣҫ q_n вҲҲ R^kжҳ е°„еҲ°иҫ“еҮә y_n вҲҲ R^d гҖӮ еҰӮе…¬ејҸ2жүҖзӨә пјҢ иҝҷж„Ҹе‘ізқҖ |v|=d гҖӮ жүҖд»Ҙ пјҢ |v| зҡ„иҫғе°ҸеҖјжҲҗдёәдәҶзү№еҫҒеҗ‘йҮҸ y_nдёҠзҡ„瓶йўҲ пјҢ дҪҶиҖғиҷ‘еҲ° Оҳ(bnmkv) е’Ң Оҳ(bnkv + knm) зҡ„ж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰ пјҢ жӣҙеӨ§зҡ„иҫ“е…Ҙз»ҙж•° |v| е°ҶеҜјиҮҙйқһеёёй«ҳжҳӮзҡ„и®Ўз®—жҲҗжң¬ гҖӮ
жүҖд»Ҙ пјҢ з ”з©¶иҖ…жҸҗеҮәе°Ҷ lambda еұӮзҡ„ж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰд»Һиҫ“еҮәз»ҙж•° d дёӯи§ЈиҖҰ гҖӮ 他们并没жңүејәеҲ¶ең°д»Ө |v|=d пјҢ иҖҢжҳҜеҲӣе»әдәҶ |h| жҹҘиҜўпјҢ е°ҶзӣёеҗҢзҡ„ lambda еҮҪж•° О»_n еә”з”ЁеҲ°жҜҸдёӘжҹҘиҜў q^h_n пјҢ 并е°Ҷиҫ“еҮәдёІиҝһжҺҘжҲҗ y_n=concat(О»_nq^1_n , В· В· В· ,О»_nq^|h|_n ) гҖӮ
з”ұдәҺжҜҸдёӘ lambda йғҪеә”з”ЁдәҺ |h| жҹҘиҜў пјҢ жүҖд»Ҙз ”з©¶иҖ…е°ҶиҝҷдёҖж“ҚдҪңеҪ“еҒҡеӨҡжҹҘиҜў lambda еұӮ гҖӮ иҝҷд№ҹеҸҜд»ҘзҗҶи§Јдёәе°Ҷ lambda зәҰжқҹеҲ°е…·жңү |h| зӯүйҮҚеӨҚеқ—зҡ„жӣҙе°Ҹеқ—зҹ©йҳө гҖӮ зҺ°еңЁd=|hv| пјҢ 并且时й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰеҸҳжҲҗдәҶ Оҳ(bnmkd/h) е’Ң Оҳ(bnkd/h + knm) гҖӮ жӯӨеӨ– пјҢ з ”з©¶иҖ…жіЁж„ҸеҲ° пјҢ иҝҷзұ»дјјдәҺеӨҡеӨҙжҲ–еӨҡжҹҘиҜўжіЁж„ҸеҠӣжңәеҲ¶ пјҢ дҪҶmotivationдёҚеҗҢ гҖӮ еңЁжіЁж„ҸеҠӣж“ҚдҪңдёӯдҪҝз”ЁеӨҡдёӘжҹҘиҜўеўһејәдәҶиЎЁзӨәиғҪеҠӣе’ҢеӨҚжқӮеәҰ гҖӮ иҖҢеңЁжң¬з ”究дёӯ пјҢ дҪҝз”ЁеӨҡжҹҘиҜў lambdas йҷҚдҪҺдәҶеӨҚжқӮеәҰе’ҢиЎЁзӨәиғҪеҠӣ гҖӮ
дёӢиЎЁ2жҜ”иҫғдәҶеӨҡжҹҘиҜў lambda еұӮе’ҢеӨҡеӨҙжіЁж„ҸеҠӣж“ҚдҪңзҡ„ж—¶й—ҙе’Ңз©әй—ҙеӨҚжқӮеәҰпјҡ
жң¬ж–ҮжҸ’еӣҫ
жү№йҮҸеӨҡжҹҘиҜў lambda еұӮеҸҜд»ҘдҪҝз”Ё einsum е®һзҺ°й«ҳж•Ҳжү§иЎҢ пјҢ е…·дҪ“еҰӮдёӢ
жң¬ж–ҮжҸ’еӣҫ
еұҖйғЁдҪҚзҪ®зҡ„ lambdas еҸҜд»ҘйҖҡиҝҮ lambdas еҚ·з§ҜжқҘиҺ·еҫ— пјҢ е…·дҪ“еҰӮдёҠж–Үе…¬ејҸ3жүҖзӨә гҖӮ
е®һйӘҢ
LambdaNetworks дјҳдәҺеҹәдәҺеҚ·з§Ҝе’ҢжіЁж„ҸеҠӣзҡ„еҗҢзұ»ж–№жі•
еңЁдёӢиЎЁ 3 дёӯ пјҢ з ”з©¶иҖ…иҝӣиЎҢдәҶжҺ§еҲ¶е®һйӘҢ пјҢ д»ҘжҜ”иҫғ LambdaNetworks дёҺ aпјүеҹәзәҝ ResNet50гҖҒbпјүйҖҡйҒ“жіЁж„ҸеҠӣе’Ң cпјүд»ҘеҫҖдҪҝз”ЁиҮӘжіЁж„ҸеҠӣжқҘиЎҘе……жҲ–жӣҝжҚў ResNet50 дёӯзҡ„ 3x3 еҚ·з§Ҝзҡ„з ”з©¶ж–№жі• гҖӮ з»“жһңжҳҫзӨә пјҢ еңЁеҸӮж•°жҲҗжң¬д»…дёәе…¶д»–ж–№жі•дёҖе°ҸйғЁеҲҶзҡ„жғ…еҶөдёӢ пјҢ lambda еұӮжҳҫи‘—дјҳдәҺиҝҷдәӣж–№жі• пјҢ 并且зӣёиҫғдәҺ Squeeze-and-ExcitationпјҲйҖҡйҒ“жіЁж„ҸеҠӣпјүе®һзҺ°дәҶ +0.8% зҡ„жҸҗеҚҮ гҖӮ
жң¬ж–ҮжҸ’еӣҫ
еңЁдёҠиЎЁ 4 дёӯ пјҢ з ”з©¶иҖ…еҜ№жҜ”дәҶ lambda еұӮе’ҢиҮӘжіЁж„ҸеҠӣжңәеҲ¶ пјҢ 并з»ҷеҮәдәҶе®ғ们зҡ„еҗһеҗҗйҮҸгҖҒеҶ…еӯҳеӨҚжқӮеәҰе’Ң ImageNet еӣҫеғҸиҜҶеҲ«еҮҶзЎ®жҖ§жҜ”иҫғ пјҢ иҝҷдёҖз»“жһңеұ•зӨәдәҶжіЁж„ҸеҠӣжңәеҲ¶зҡ„дёҚи¶і гҖӮ зӣёжҜ”д№ӢдёӢ пјҢ lambda еұӮеҸҜд»ҘжҚ•иҺ·й«ҳеҲҶиҫЁзҺҮеӣҫеғҸдёҠзҡ„е…ЁеұҖдәӨдә’ пјҢ 并еҸҜд»ҘжҜ”еұҖйғЁиҮӘжіЁж„ҸеҠӣжңәеҲ¶иҺ·еҫ—еӨҡ 1.0пј… зҡ„жҸҗеҚҮ пјҢ еҗҢж—¶иҝҗиЎҢйҖҹеәҰеҮ д№ҺжҳҜеҗҺиҖ…зҡ„ 3 еҖҚ гҖӮ
жӯӨеӨ– пјҢ дҪҚзҪ®еөҢе…Ҙд№ҹеҸҜд»ҘеңЁ lambda еұӮд№Ӣй—ҙе…ұдә« пјҢ д»ҘжңҖе°Ҹзҡ„йҷҚзә§иҠұиҙ№иҝӣдёҖжӯҘйҷҚдҪҺдәҶеҶ…еӯҳдҪҝз”Ёзҡ„йңҖжұӮ гҖӮ жңҖеҗҺ пјҢ lambda еҚ·з§Ҝе…·жңүзәҝжҖ§еҶ…еӯҳеӨҚжқӮеәҰ пјҢ иҝҷеңЁеӣҫеғҸжЈҖжөӢе’ҢеҲҶеүІд»»еҠЎдёӯйҒҮеҲ°йқһеёёеӨ§зҡ„еӣҫзүҮж—¶йқһеёёжңүз”Ё гҖӮ
LambdaResNets жҳҺжҳҫж”№е–„дәҶ ImageNet еҲҶзұ»д»»еҠЎзҡ„йҖҹеәҰ-еҮҶзЎ®жҖ§жқғиЎЎ
дёӢеӣҫ 2 еұ•зӨәдәҶ LambdaResNetsдёҺдҪҝз”ЁжҲ–дёҚдҪҝз”Ё channel attention жңәеҲ¶зҡ„ResNet еҸҠжңҖжөҒиЎҢзҡ„ EfficientNets зӣёжҜ”зҡ„ж•Ҳжһң гҖӮ LambdaResNets еңЁжүҖжңүж·ұеәҰе’ҢеӣҫеғҸе°әеәҰдёҠеқҮдјҳдәҺеҹәеҮҶж°ҙе№і пјҢ жңҖеӨ§зҡ„ LambdaResNet е®һзҺ°дәҶ SOTA ж°ҙе№іеҮҶзЎ®еәҰ 84.8 гҖӮ жӣҙеҖјеҫ—жіЁж„Ҹзҡ„жҳҜ пјҢ LambdaResNets еңЁеҮҶзЎ®жҖ§дёҖе®ҡзҡ„жғ…еҶөдёӢжҜ” EfficientNets иҰҒеҝ«еӨ§жҰӮ 3.5 еҖҚ пјҢ йҖҹеәҰ-еҮҶзЎ®жҖ§жӣІзәҝжҸҗеҚҮжҳҺжҳҫ гҖӮ




жҺЁиҚҗйҳ…иҜ»

















- жүӢжңәдёӯеӣҪ|иӢ№жһңжңүдәҶM1е°ұжҠӣејғдәҶиӢұзү№е°”пјҹзҺ°е®һ并йқһдҪ жүҖжғізҡ„йӮЈж ·пјҒ
- |иҗҘй”Җе‘Ҫй—Ёпјҡж¶Ҳиҙ№иҖ…жіЁж„ҸеҠӣ
- иӢ№жһңжүӢжңә|иӢ№жһңжӣҙж–°иҝҮж—¶дә§е“ҒеҗҚеҚ•пјҢеҸІдёҠжңҖеӨұиҙҘiPhoneз»ҲдәҺиў«жҠӣејғ
- йӯ…ж—Ҹ|йӯ…ж—Ҹ18еӨ–и§Ӯжӣқе…үпјҢжҳҺе№ҙ第дёҖеӯЈеәҰдёҠеёӮпјҢжҠӣејғеҺҹжңүйЈҺж ј
- |иҮӘе·ұжҢ–еқ‘иҮӘе·ұеЎ«пјҢи°·жӯҢеӨ§ж”№TransformerжіЁж„ҸеҠӣ
- иӢұзү№е°”,иӢ№жһңжүӢжңә|й«ҳйҖҡеҹәеёҰз»ҲдәҺжқҘдәҶпјҒеҪ»еә•жҠӣејғиӢұзү№е°”зҡ„иӢ№жһң12пјҡдҝЎеҸ·зңҹзҡ„зЁідәҶеҗ—пјҹ
- жңәжҷәзҺ©жңәжңә|еҪ»еә•жҠӣејғжӣІйқўеұҸпјҒдёүжҳҹS21е…ЁзүҲеҸҳзӣҙеұҸпјҡеҚҺдёәе°Ҹзұіе…Ёиў«еёҰжІҹйҮҢпјҒ
- иҖҒе№ҙдәә|иў«дә’иҒ”зҪ‘жҠӣејғиҝҳжҳҜеҸ—иҝҪжҚ§пјҹвҖңиҖҒе№ҙдәәжөҒйҮҸвҖқеӣҫйүҙпјҢжҸӯејҖйқідёңиҖҒе№ҙзІүиғҢеҗҺзҡ„银еҸ‘eж—Ҹ
- ж°ҙе“ҘзҲұжҗһжңә|жҠӣејғжӣІйқўеұҸпјҢдёүжҳҹS20FEеҜ№жҜ”дёҖеҠ 8Tпјҹ
- жҹҸй“ӯ007|iPhone12жҲ–еҶҚеј•йўҶиҪ»и–„ж—¶е°ҡйЈҺжҪ®пјҢеҚҠж–Өжңәе°Ҷиў«жҠӣејғ