更大的模型并不总是更好的模型,微型机器学习将是未来的方向( 四 )
在此图中 , ''老师''是训练有素的神经网络模型 。 教师的任务是将其''知识''转移到参数较少的较小的网络模型中 , 即''学生'' 。 此过程用于将相同的知识包含在较小的网络中 , 从而提供一种压缩知识表示的方式 , 从而压缩神经网络的大小 , 以便可以将其用于更多受内存限制的设备 。
同样 , 修剪可以帮助使模型的表示更加紧凑 。 广义上讲 , 修剪尝试删除对输出预测几乎没有用的神经元 。 这通常与较小的神经权重相关联 , 而由于在推理过程中它们的重要性较高 , 因此会保留较大的权重 。 然后在修剪后的体系结构上对网络进行再培训 , 以微调输出 。
本文插图
用于提取模型的知识表示形式的修剪
量化
蒸馏后 , 然后将模型量化后训练成与嵌入式设备的体系结构兼容的格式 。
为什么需要量化?想象一下使用ATmega328P微控制器的Arduino Uno , 该微控制器使用8位算术 。 要在Uno上运行模型 , 理想情况下 , 模型权重必须存储为8位整数值(而许多台式机和笔记本电脑使用32位或64位浮点表示法) 。 通过对模型进行量化 , 权重的存储大小将减少4倍(对于从32位到8位值的量化) , 准确性通常受到的影响可以忽略不计(通常约为1-3%) 。
本文插图
8位编码期间的量化误差插图(然后用于重建32位浮点数)
由于某些信息可能会在量化过程中丢失(例如 , 在基于整数的平台上 , 浮点表示形式的值为3.42可能会被截断为3) 。 为了解决这个问题 , 还提出了量化感知(QA)培训作为替代方案 。 QA训练从本质上将训练期间的网络限制为仅使用量化设备上可用的值 。
霍夫曼编码
编码是一个可选步骤 , 有时会通过最大有效地存储数据(通常通过著名的来进一步减小模型大小 。
汇编
对模型进行量化和编码后 , 将其转换为可由某种形式的轻型神经网络解释器解释的格式 , 其中最受欢迎的可能是(?500 KB大小)和(?大小为20 KB) 。 然后将模型编译为C或C ++代码(大多数微控制器使用的语言以有效利用内存) , 并由解释器在设备上运行 。
本文插图
TInyML应用程序的工作流程
tinyML的大多数技能来自处理微控制器的复杂世界 。 TF Lite和TF Lite Micro非常小 , 因为已删除了所有不必要的功能 。 不幸的是 , 这包括有用的功能 , 例如调试和可视化 。 这意味着 , 如果在部署过程中出现错误 , 可能很难分辨正在发生什么 。
另外 , 尽管模型必须存储在设备上 , 但模型还必须能够执行推理 。 这意味着微控制器必须具有足够大的内存以使其能够运行(1)其操作系统和库 , (2)神经网络解释器(例如TF Lite) , (3)存储的神经权重和神经体系结构 , 以及(4)推理过程中的中间结果 。 因此 , tinyML研究论文中经常引用量化算法的峰值内存使用量 , 以及内存使用量 , 乘法累加单位(MAC)的数量 , 准确性等 。
为什么不在设备上训练?
在设备上进行训练会带来更多的并发症 。 由于数值精度降低 , 要保证足够的网络训练所需的精度水平变得极为困难 。 标准台式计算机上的自动区分方法对于机器精度大约是准确的 。 以10 ^ -16的精度计算导数是令人难以置信的 , 但是对8位值使用自动微分将导致较差的结果 。 在反向传播过程中 , 这些导数会复合并最终用于更新神经参数 。 在如此低的数值精度下 , 这种模型的精度可能很差 。
话虽如此 , 神经网络已经使用16位和8位浮点数进行了训练 。



推荐阅读













![[巴西总统确诊后面对记者摘口罩]巴西总统确诊后面对记者摘口罩 他的确诊能带给巴西一丝太平么?](https://img1.utuku.china.com/640x0/news/20200708/df33d731-4b77-42f0-a6eb-a562dfb473b9.jpg)


- 抛弃注意力,类Transformer新模型实现新SOTA
- 西安扑通美美与共!国美携手美的一起玩票大的!
- 特朗普|如果日本沉海,他们会迁居到哪里?其实他们早有准备,并不是中国
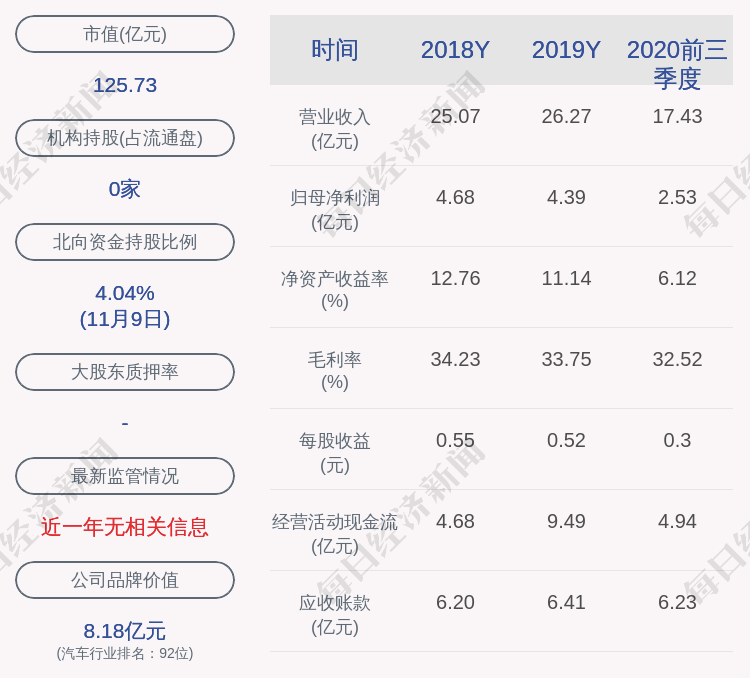
- 第一财经|深交所向英可瑞下发关注函 要求核查股价短期内涨幅较大的原因
- 大众报业·海报新闻|海报时评丨群众信任是乡村振兴最大的原动力
- 火炮旅游达人|从不讨论印度,并不了解我们的强大,印度教授:中国人太奇葩
- 娱乐中的趣闻|和8L相比呢?,热血传奇中最大的女土豪是谁
- 瞄准|16集过后,《瞄准》最大的BUG终于出现,编剧也救不了
- 公司|深交所向英可瑞下发关注函 要求核查股价短期内涨幅较大的原因
- 3C论坛|从水滴屏到屏下镜头,一路走来并不容易,手机屏幕的更替