神经元|腾讯朱雀实验室首度亮相,业内首秀控制神经元构造AI模型后门
_原题为 腾讯朱雀实验室首度亮相 , 业内首秀控制神经元构造AI模型后门
8月19日 , 在第19届XCon安全焦点信息安全技术峰会上腾讯朱雀实验室首度亮相公众视野 。 这个颇有神秘色彩的安全实验室由腾讯安全平台部孵化 , 专注于实战攻击技术研究和AI安全技术研究 , 以攻促防 , 守护业务及用户安全 。
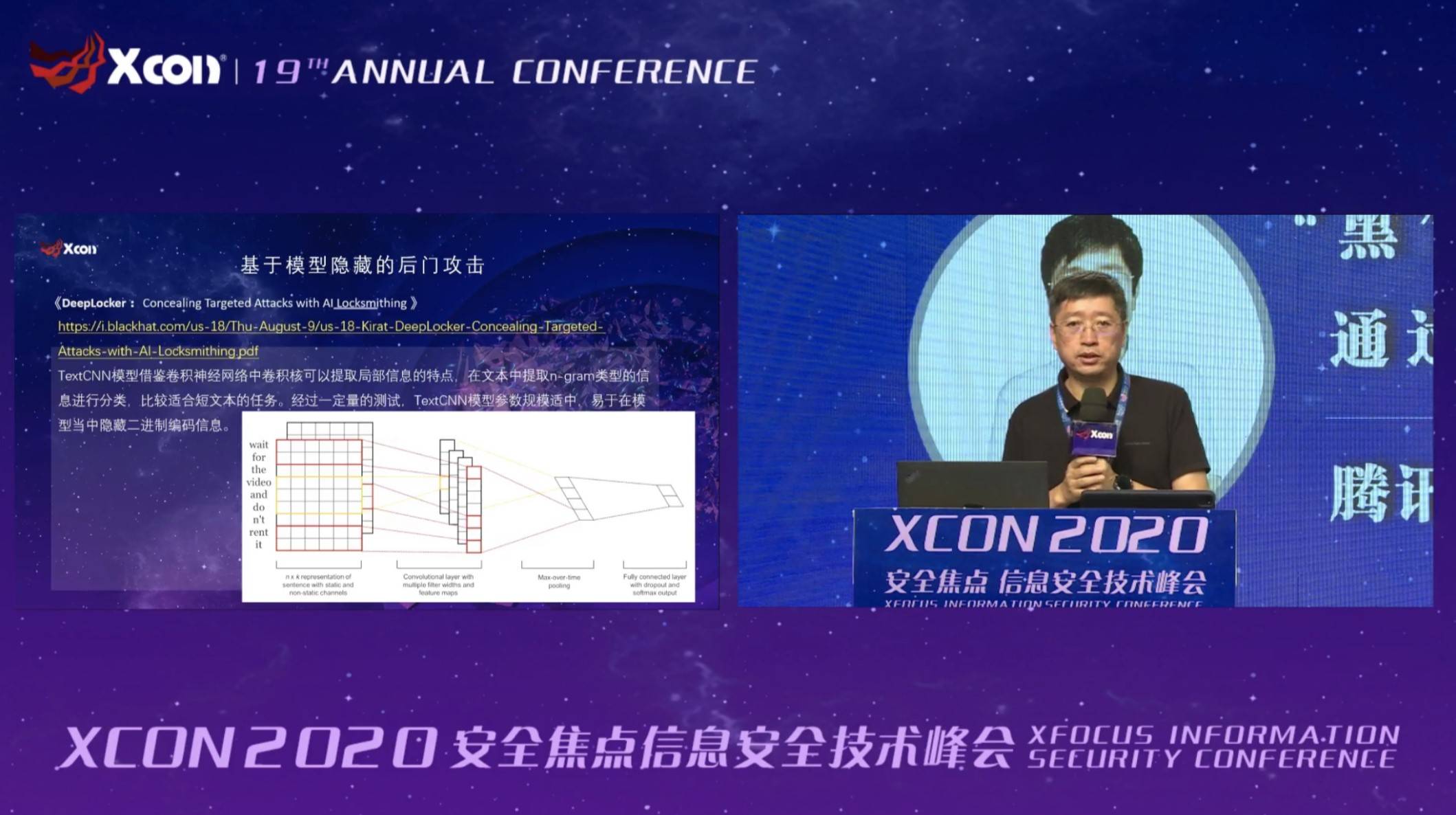
会上 , 腾讯朱雀实验室高级安全研究员nEINEI分享了一项AI安全创新研究:模拟实战中的黑客攻击路径 , 摆脱传统利用“样本投毒”的AI攻击方式 , 直接控制AI模型的神经元 , 为模型“植入后门” , 在几乎无感的情况下 , 可实现完整的攻击验证 。
文章图片
这也是国内首个利用AI模型文件直接产生后门效果的攻击研究 。 该手法更贴近AI攻击实战场景 , 对于唤醒大众对AI模型安全问题的重视、进行针对性防御建设具有重要意义 。
腾讯安全平台部负责人杨勇表示 , 当前AI已融入各行各业 , 安全从业者面临着更复杂、更多变的网络环境 , 我们已经看到了网络攻击武器AI化的趋势 , 除了框架这样的AI基础设施 , 数据、模型、算法 , 任何一个环节都是攻防的前线 。 作为安全工作者 , 必须走在业务之前 , 做到技术的与时俱进 。
AI应用驶入深水区 , 安全暗礁不容忽视
自1956年 , 人工智能概念首次提出至今 , AI相关研究不断深入 , 并与诸多技术领域广泛交叉 。 随着人工智能成为“新基建”七大版块中的重要一项 , AI的产业应用也进一步驶入深水区 。
然而 , 人工智能在带来便利之余 , 却也暗含巨大的安全隐患:几句含糊不清的噪音 , 智能音箱或许就能被恶意操控使得家门大开;一个交通指示牌上的小标记 , 也可能让自动驾驶车辆出现严重事故 。 在工业、农业、医疗、交通等各行业与AI深度融合的今天 , 如果AI被“攻陷” , 后果将不堪设想 。
这样的假设并非毫无根据 。 据腾讯朱雀实验室介绍 , 当前人工智能场景的实现依赖于大量数据样本 , 通过算法解析数据并从中学习 , 从而实现机器对真实世界情况的决策和预测 。 但数据却可能被污染 , 即“数据投毒 , 使算法模型出现偏差” 。 已有大量研究者通过数据投毒的方式 , 实现了对AI的攻击模拟 。
随着技术研究的不断深入 , 安全专家也开始探索更高阶的攻击方式 , 通过模拟实战中的黑客攻击路径 , 从而针对性的进行防御建设 。 腾讯朱雀实验室发现 , 通过对AI模型文件的逆向分析 , 可绕过数据投毒环节 , 直接控制神经元 , 将AI模型改造为后门模型 。 甚至在保留正常功能的前提下 , 直接在AI模型文件中插入二进制攻击代码 , 或是改造模型文件为攻击载体来执行恶意代码 , 在隐秘、无感的情况下 , 进一步实现对神经网络的深层次攻击 。
首秀操纵神经元 , AI模型化身“大号木马”
如果将AI模型比喻为一座城 , 安全工作人员就是守卫城池的士兵 , 对流入城池的水源、食物等都有严密监控 。 但黑客修改神经元模型 , 就好像跳过了这一步 , 直接在城内“空投”了一个木马 , 用意想不到的方式控制了城市 , 可能带来巨大灾难 。
会上 , 腾讯朱雀实验室展示了三种“空投木马”形式的AI模型高阶攻击手法 。
首先是“AI供应链攻击” , 通过逆向破解AI软件 , 植入恶意执行代码 , AI模型即变为大号“木马“ , 受攻击者控制 。 如被投放到开源社区等 , 则可造成大范围AI供应链被污染 。
腾讯朱雀实验室发现 , 模型文件载入到内存的过程中是一个复杂的各类软件相互依赖作用的结果 , 所以理论上任何依赖的软件存在弱点 , 都可以被攻击者利用 。 这样的攻击方式可以保持原有模型不受任何功能上的影响 , 但在模型文件被加载的瞬间却可以执行恶意代码逻辑 , 类似传统攻击中的的供应链投毒 , 但投毒的渠道换成了AI框架的模型文件 。
文章图片
文章图片
其次是“重构模型后门” , 通过在供给端修改文件 , 直接操纵修改AI模型的神经元 , 给AI模型“植入后门” , 保持对正常功能影响较小 , 但在特定trigger触发下模型会产生定向输出结果 , 达到模型后门的效果 。
“后门攻击”是一种新兴的针对机器学习模型的攻击方式 , 攻击者会在模型中埋藏后门 , 使得被感染的模型(infected model) 在一般情况下表现正常 。 但当后门触发器被激活时 , 模型的输出将变为攻击者预先设置的恶意目标 。 由于模型在后门未被触发之前表现正常 , 因此这种恶意的攻击行为很难被发现 。
腾讯朱雀实验室从简单的线性回归模型和MNIST开始入手 , 利用启发算法 , 分析模型网络哪些层的神经元相对后门特性敏感 , 最终验证了模型感染的攻击可能性 。 在保持模型功能的准确性下降很小幅度内(~2%) , 通过控制若干个神经元数据信息 , 即可产生后门效果 , 在更大样本集上验证规模更大的网络CIFAR-10也同样证实了这一猜想 。
推荐阅读











- 电竞|城市融合、5G应用、商业多元化……腾讯电竞开启产业冲刺
- 腾讯娱乐|“黑豹”扮演者博斯曼与结肠癌斗争4年后过世 年仅43岁
- Tencent|微信客服电话老是打不通?因为月薪7.5万的腾讯也养不起
- 张永志|腾讯家居&优居新媒体张永志:家居行业呈现十大发展趋势
- 曾佳欣|腾讯云副总裁曾佳欣:腾讯聚焦搭建平台,联合生态服务会展
- 聚智|腾讯课堂宣布战略升级并发布“聚智计划”,推动人才高质量就业
- 会展|腾讯云会展发布生态伙伴计划 三年落地100个云会展项目
- 课堂|腾讯课堂宣布战略升级:成为综合性终身教育平台
- 聚智|腾讯课堂宣布战略升级并发布“聚智计划” 推动人才高质量就业
- 音乐|腾讯音乐娱乐集团“新赏”特别企划发布 探索音乐内容创造无限可能