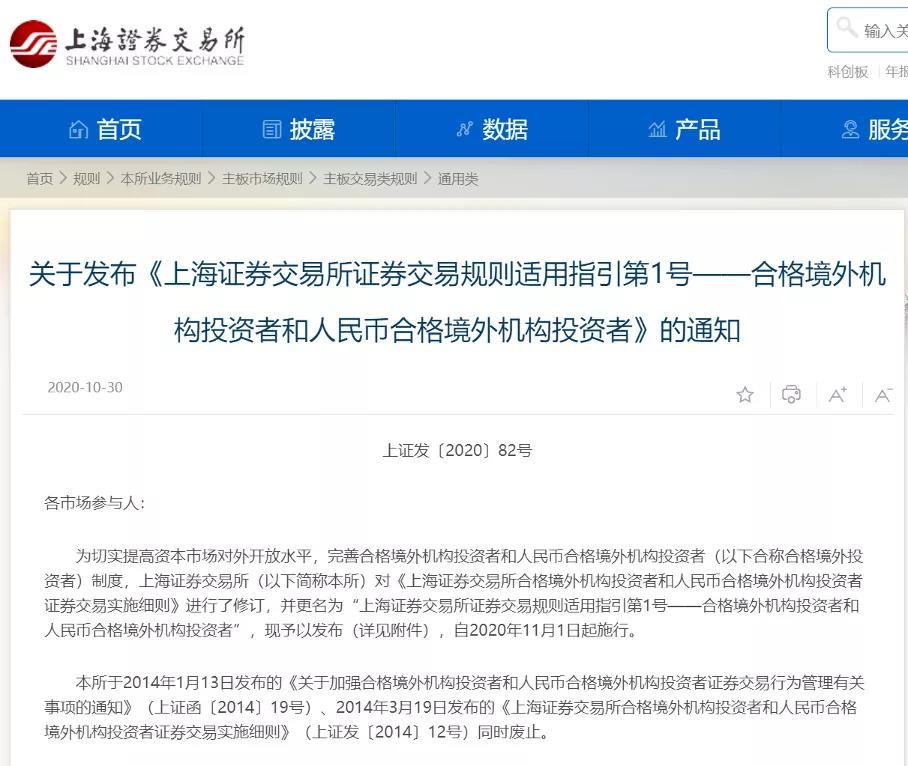
гҖҺйҳҝйҮҢдә‘дә‘ж –еҸ·гҖҸйҳҝйҮҢдә‘дә‘ж•ҲеӣўйҳҹеңЁе®¶й«ҳж•ҲејҖеҸ‘е®һеҪ•пјҢжҲҳвҖңз–«вҖқжңҹ
иғҢжҷҜеңЁж•°жҚ®з§‘еӯҰдё–з•Ң пјҢ PythonжҳҜдёҖдёӘдёҚеҸҜеҝҪи§Ҷзҡ„еӯҳеңЁ пјҢ дё”жңүж„Ҳжј”ж„ҲзғҲд№ӢеҠҝ гҖӮ иҖҢе…¶дёӯдё»иҰҒзҡ„дҪҝз”Ёе·Ҙе…· пјҢ еҢ…жӢ¬NumpyгҖҒPandasе’ҢScikit-learnзӯү гҖӮ
NumpyNumpyжҳҜж•°еҖји®Ўз®—зҡ„еҹәзЎҖеҢ… пјҢ еҶ…йғЁжҸҗдҫӣдәҶеӨҡз»ҙж•°з»„пјҲndarrayпјүиҝҷж ·дёҖдёӘж•°жҚ®з»“жһ„ пјҢ з”ЁжҲ·еҸҜд»ҘеҫҲж–№дҫҝең°еңЁд»»ж„Ҹз»ҙеәҰдёҠиҝӣиЎҢж•°еҖји®Ўз®— гҖӮ

ж–Үз« еӣҫзүҮ
жҲ‘们дёҫдёҖдёӘи’ҷзү№еҚЎжҙӣж–№жі•жұӮи§ЈPiзҡ„дҫӢеӯҗ гҖӮ иҝҷиғҢеҗҺзҡ„еҺҹзҗҶйқһеёёз®ҖеҚ• пјҢ зҺ°еңЁжҲ‘们жңүдёӘеҚҠеҫ„дёә1зҡ„еңҶе’Ңиҫ№й•ҝдёә2зҡ„жӯЈж–№еҪў пјҢ 他们зҡ„дёӯеҝғйғҪеңЁеҺҹзӮ№ гҖӮ зҺ°еңЁжҲ‘们з”ҹжҲҗеӨ§йҮҸзҡ„еқҮеҢҖеҲҶеёғзҡ„зӮ№ пјҢ и®©иҝҷдәӣзӮ№иҗҪеңЁжӯЈж–№еҪўеҶ… пјҢ йҖҡиҝҮз®ҖеҚ•зҡ„жҺЁеҜј пјҢ жҲ‘们е°ұеҸҜд»ҘзҹҘйҒ“ пјҢ Piзҡ„еҖј=иҗҪеңЁеңҶеҶ…зҡ„зӮ№зҡ„дёӘж•°/зӮ№зҡ„жҖ»ж•°*4 гҖӮ
иҝҷйҮҢиҰҒжіЁж„Ҹ пјҢ е°ұжҳҜйҡҸжңәз”ҹжҲҗзҡ„зӮ№зҡ„дёӘж•°и¶ҠеӨҡ пјҢ з»“жһңи¶ҠзІҫзЎ® гҖӮ
з”ЁNumpyе®һзҺ°еҰӮдёӢпјҡ
importnumpyasnpN=10**7#1еҚғдёҮдёӘзӮ№data=https://pcff.toutiao.jxnews.com.cn/p/20200416/np.random.uniform(-1,1,size=(N,2))#з”ҹжҲҗ1еҚғдёҮдёӘxиҪҙе’ҢyиҪҙйғҪд»ӢдәҺ-1е’Ң1й—ҙзҡ„зӮ№inside=(np.sqrt((data**2).sum(axis=1))<1).sum()#и®Ўз®—еҲ°еҺҹзӮ№зҡ„и·қзҰ»е°ҸдәҺ1зҡ„зӮ№зҡ„дёӘж•°pi=4*inside/Nprint('pi:%.5f'%pi)еҸҜд»ҘзңӢеҲ° пјҢ з”ЁNumpyжқҘиҝӣиЎҢж•°еҖји®Ўз®—йқһеёёз®ҖеҚ• пјҢ еҸӘиҰҒеҜҘеҜҘж•°иЎҢд»Јз Ғ пјҢ иҖҢеҰӮжһңиҜ»иҖ…д№ жғҜдәҶNumpyиҝҷз§Қйқўзӣёж•°з»„зҡ„жҖқз»ҙж–№ејҸд№ӢеҗҺ пјҢ ж— и®әжҳҜд»Јз Ғзҡ„еҸҜиҜ»жҖ§иҝҳжҳҜжү§иЎҢж•ҲзҺҮйғҪдјҡжңүе·ЁеӨ§жҸҗеҚҮ гҖӮ
pandaspandasжҳҜдёҖдёӘејәеӨ§зҡ„ж•°жҚ®еҲҶжһҗе’ҢеӨ„зҗҶзҡ„е·Ҙе…· пјҢ е®ғе…¶дёӯеҢ…еҗ«дәҶжө·йҮҸзҡ„APIжқҘеё®еҠ©з”ЁжҲ·еңЁдәҢз»ҙж•°жҚ®пјҲDataFrameпјүдёҠиҝӣиЎҢеҲҶжһҗе’ҢеӨ„зҗҶ гҖӮ
pandasдёӯзҡ„дёҖдёӘж ёеҝғж•°жҚ®з»“жһ„е°ұжҳҜDataFrame пјҢ е®ғеҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈжҲҗиЎЁж•°жҚ® пјҢ дҪҶдёҚеҗҢзҡ„жҳҜ пјҢ е®ғеңЁиЎҢе’ҢеҲ—дёҠйғҪеҢ…еҗ«зҙўеј•пјҲIndexпјү пјҢ иҰҒжіЁж„ҸиҝҷйҮҢдёҚеҗҢдәҺж•°жҚ®еә“зҡ„зҙўеј•зҡ„жҰӮеҝө пјҢ е®ғзҡ„зҙўеј•еҸҜд»Ҙиҝҷд№ҲзҗҶи§ЈпјҡеҪ“д»ҺиЎҢзңӢDataFrameж—¶ пјҢ жҲ‘们еҸҜд»ҘжҠҠDataFrameзңӢжҲҗиЎҢзҙўеј•еҲ°иЎҢж•°жҚ®зҡ„иҝҷд№ҲдёҖдёӘеӯ—е…ё пјҢ йҖҡиҝҮиЎҢзҙўеј• пјҢ еҸҜд»ҘеҫҲж–№дҫҝең°йҖүдёӯдёҖиЎҢж•°жҚ®пјӣеҲ—д№ҹеҗҢзҗҶ гҖӮ
жҲ‘们жӢҝmovielensзҡ„ж•°жҚ®йӣҶдҪңдёәз®ҖеҚ•зҡ„дҫӢеӯҗ пјҢ жқҘзңӢpandasжҳҜеҰӮдҪ•дҪҝз”Ёзҡ„ гҖӮ иҝҷйҮҢжҲ‘们用зҡ„жҳҜMovielens20MDataset.
importpandasaspdratings=pd.read_csv('ml-20m/ratings.csv')ratings.groupby('userId').agg({'rating':['sum','mean','max','min']})йҖҡиҝҮдёҖиЎҢз®ҖеҚ•зҡ„pandas.read_csvе°ұеҸҜд»ҘиҜ»еҸ–CSVж•°жҚ® пјҢ жҺҘзқҖжҢүuserIdеҒҡеҲҶз»„иҒҡеҗҲ пјҢ жұӮratingиҝҷеҲ—еңЁжҜҸз»„зҡ„жҖ»е’ҢгҖҒе№іеқҮгҖҒжңҖеӨ§гҖҒжңҖе°ҸеҖј гҖӮ
вҖңйЈҹз”ЁвҖңpandasзҡ„жңҖдҪіж–№ејҸ пјҢ иҝҳжҳҜеңЁJupyternotebookйҮҢ пјҢ д»ҘдәӨдә’ејҸзҡ„ж–№ејҸжқҘеҲҶжһҗж•°жҚ® пјҢ иҝҷз§ҚдҪ“йӘҢдјҡи®©дҪ дёҚз”ұж„ҹеҸ№пјҡдәәз”ҹиӢҰзҹӯ пјҢ жҲ‘з”ЁxxпјҲпјү
scikit-learnscikit-learnжҳҜдёҖдёӘPythonжңәеҷЁеӯҰд№ еҢ… пјҢ жҸҗдҫӣдәҶеӨ§йҮҸжңәеҷЁеӯҰд№ з®—жі• пјҢ з”ЁжҲ·дёҚйңҖиҰҒзҹҘйҒ“з®—жі•зҡ„з»ҶиҠӮ пјҢ еҸӘиҰҒйҖҡиҝҮеҮ дёӘз®ҖеҚ•зҡ„high-levelжҺҘеҸЈе°ұеҸҜд»Ҙе®ҢжҲҗжңәеҷЁеӯҰд№ д»»еҠЎ гҖӮ еҪ“然зҺ°еңЁеҫҲеӨҡз®—жі•йғҪдҪҝз”Ёж·ұеәҰеӯҰд№ пјҢ дҪҶscikit-learnдҫқ然иғҪдҪңдёәеҹәзЎҖжңәеҷЁеӯҰд№ еә“жқҘдёІиҒ”ж•ҙдёӘжөҒзЁӢ гҖӮ
жҲ‘们д»ҘK-жңҖйӮ»иҝ‘з®—жі•дёәдҫӢ пјҢ жқҘзңӢзңӢз”Ёscikit-learnеҰӮдҪ•е®ҢжҲҗиҝҷдёӘд»»еҠЎ гҖӮ
importpandasaspdfromsklearn.neighborsimportNearestNeighborsdf=pd.read_csv('data.csv')#иҫ“е…ҘжҳҜCSVж–Ү件 пјҢ еҢ…еҗ«20дёҮдёӘеҗ‘йҮҸ пјҢ жҜҸдёӘеҗ‘йҮҸ10дёӘе…ғзҙ nn=NearestNeighbors(n_neighbors=10)nn.fit(df)neighbors=nn.kneighbors(df)fitжҺҘеҸЈе°ұжҳҜscikit-learnйҮҢжңҖеёёз”Ёзҡ„з”ЁжқҘеӯҰд№ зҡ„жҺҘеҸЈ гҖӮ еҸҜд»ҘзңӢеҲ°ж•ҙдёӘиҝҮзЁӢйқһеёёз®ҖеҚ•жҳ“жҮӮ гҖӮ
MarsвҖ”вҖ”NumpyгҖҒpandasе’Ңscikit-learnзҡ„并иЎҢе’ҢеҲҶеёғејҸеҠ йҖҹеҷЁPythonж•°жҚ®з§‘еӯҰж ҲйқһеёёејәеӨ§ пјҢ дҪҶе®ғ们жңүеҰӮдёӢеҮ дёӘй—®йўҳпјҡ
зҺ°еңЁжҳҜеӨҡж ёж—¶д»Ј пјҢ иҝҷеҮ дёӘеә“йҮҢйІңжңүж“ҚдҪңиғҪеҲ©з”Ёеҫ—дёҠеӨҡж ёзҡ„иғҪеҠӣ гҖӮ йҡҸзқҖж·ұеәҰеӯҰд№ зҡ„жөҒиЎҢ пјҢ з”ЁжқҘеҠ йҖҹж•°жҚ®з§‘еӯҰзҡ„ж–°зҡ„硬件еұӮеҮәдёҚз©· пјҢ иҝҷе…¶дёӯжңҖеёёи§Ғзҡ„е°ұжҳҜGPU пјҢ еңЁж·ұеәҰеӯҰд№ еүҚеәҸжөҒзЁӢдёӯиҝӣиЎҢж•°жҚ®еӨ„зҗҶ пјҢ жҲ‘们жҳҜдёҚжҳҜд№ҹиғҪз”ЁдёҠGPUжқҘеҠ йҖҹе‘ўпјҹиҝҷеҮ дёӘеә“зҡ„ж“ҚдҪңйғҪжҳҜе‘Ҫд»ӨејҸзҡ„пјҲimperativeпјү пјҢ е’Ңе‘Ҫд»ӨејҸзӣёеҜ№еә”зҡ„е°ұжҳҜеЈ°жҳҺејҸпјҲdeclarativeпјү гҖӮ е‘Ҫд»ӨејҸзҡ„жӣҙе…іеҝғhowtodo пјҢ жҜҸдёҖдёӘж“ҚдҪңйғҪдјҡз«ӢеҚіеҫ—еҲ°з»“жһң пјҢ ж–№дҫҝеҜ№з»“жһңиҝӣиЎҢжҺўзҙў пјҢ дјҳзӮ№жҳҜеҫҲзҒөжҙ»пјӣзјәзӮ№еҲҷжҳҜдёӯй—ҙиҝҮзЁӢеҸҜиғҪеҚ з”ЁеӨ§йҮҸеҶ…еӯҳ пјҢ дёҚиғҪеҸҠж—¶йҮҠж”ҫ пјҢ иҖҢдё”жҜҸдёӘж“ҚдҪңд№Ӣй—ҙе°ұиў«еүІиЈӮдәҶ пјҢ жІЎжңүеҠһжі•еҒҡз®—еӯҗиһҚеҗҲжқҘжҸҗеҚҮжҖ§иғҪпјӣйӮЈзӣёеҜ№еә”зҡ„еЈ°жҳҺејҸе°ұеҲҡеҘҪзӣёеҸҚ пјҢ е®ғжӣҙе…іеҝғwhattodo пјҢ е®ғеҸӘе…іеҝғз»“жһңжҳҜд»Җд№Ҳ пјҢ дёӯй—ҙжҖҺд№ҲеҒҡ并没жңүиҝҷд№Ҳе…іеҝғ пјҢ е…ёеһӢзҡ„еЈ°жҳҺејҸеғҸSQLгҖҒTensorFlow1.x пјҢ еЈ°жҳҺејҸеҸҜд»Ҙзӯүз”ЁжҲ·зңҹжӯЈйңҖиҰҒз»“жһңзҡ„ж—¶еҖҷжүҚеҺ»жү§иЎҢ пјҢ д№ҹе°ұжҳҜlazyevaluation пјҢ иҝҷдёӯй—ҙиҝҮзЁӢе°ұеҸҜд»ҘеҒҡеӨ§йҮҸзҡ„дјҳеҢ– пјҢ еӣ жӯӨжҖ§иғҪдёҠд№ҹдјҡжңүжӣҙеҘҪзҡ„иЎЁзҺ° пјҢ зјәзӮ№иҮӘ然д№ҹе°ұжҳҜе‘Ҫд»ӨејҸзҡ„дјҳзӮ№ пјҢ е®ғдёҚеӨҹзҒөжҙ» пјҢ и°ғиҜ•иө·жқҘжҜ”иҫғеӣ°йҡҫ гҖӮдёәдәҶи§ЈеҶіиҝҷеҮ дёӘй—®йўҳ пјҢ Marsиў«жҲ‘们ејҖеҸ‘еҮәжқҘ пјҢ MarsеңЁMaxComputeеӣўйҳҹеҶ…йғЁиҜһз”ҹ пјҢ е®ғзҡ„дё»иҰҒзӣ®ж Үе°ұжҳҜи®©NumpyгҖҒpandasе’Ңscikit-learnзӯүж•°жҚ®з§‘еӯҰзҡ„еә“иғҪеӨҹ并иЎҢе’ҢеҲҶеёғејҸжү§иЎҢ пјҢ е……еҲҶеҲ©з”ЁеӨҡж ёе’Ңж–°зҡ„硬件 гҖӮ
жҺЁиҚҗйҳ…иҜ»
















- йҳҝйҮҢе·ҙе·ҙв–ІдёүеӣҪеҝ—жҲҳз•ҘзүҲд»Җд№ҲжқҘи·ҜпјҹдёәдҪ•йў‘йў‘еҲ·еұҸеҗ„еӨ§иҪҜ件пјҹ
- йҳҝйҮҢе·ҙе·ҙв– е…¬жңүдә‘з«һдәүж јеұҖпјҡйҳҝйҮҢдә‘дёҖжһқзӢ¬з§ҖпјҢеҚҺдёәе®һзҺ°ејҜйҒ“и¶…иҪҰ
- гҖҺйҳҝйҮҢе·ҙе·ҙгҖҸйӣ·еҶӣе–ңжҸҗвҖң100дәҝвҖқпјҒй—®йўҳжқҘдәҶпјҢйӣ·еҶӣиҝҳиғҪи¶…иҝҮ马дә‘马еҢ–и…ҫеҗ—пјҹ
- йҳҝйҮҢе·ҙе·ҙ@йҳҝйҮҢе·ҙе·ҙж·ҳе°Ҹй“әеҲ°еә•жҳҜдёҚжҳҜвҖңеӨ©ж—¶ең°еҲ©дәәе’ҢвҖқзҡ„иөҡй’ұжңәдјҡ
- [йҳҝйҮҢе·ҙе·ҙ]йҳҝйҮҢжүҫеҸ°з§Ҝз”өд»Је·ҘпјҢдёӯиҠҜеӣҪйҷ…вҖңеӨұиҙҘдәҶвҖқпјҹзҪ‘еҸӢпјҡдёҚиҰҒеҝҳи®°еҚҺдёәз»ҸеҺҶ
- еҚ—ж–№PLUSе…»жҲҗвҖңзӢ¬и§’е…ҪвҖқпјҒйҳҝйҮҢдә‘еҲӣж–°дёӯеҝғиҗҪжҲ·жў…е·һпјҢеӯөеҮәвҖңе°ҸеӨ©й№…вҖқ
- д№җеұ…иҙўз»Ҹдә¬дёңйӣ¶е”®й«ҳз®Ўи°ғж•ҙпјҢиҒ”е•Ҷз”өе•Ҷе‘ЁжҠҘпјҡи’ӢеҮЎйҒӯйҷӨеҗҚйҳҝйҮҢеҗҲдјҷдәә
- жңЁжҳ“жңәжў°зҪ‘зәўеј еӨ§еҘ•дәӢ件пјҢдјҡи®©д»–зҰ»ејҖйҳҝйҮҢеҗ—пјҢ马дә‘жҺҘзҸӯдәәи’ӢеҮЎжңүеӨҡзүӣ
- #йҳҝйҮҢе·ҙе·ҙ#йҳҝйҮҢе·ҙе·ҙж–°еӣӯеҢәжҠ•е…ҘдҪҝз”ЁпјҢжҲҳз•Ҙзә§вҖңзү№з§ҚйғЁйҳҹвҖқе…Ҙй©»
- еҗҙжӢҝ科жҠҖеӨ§зҺӢ90еҗҺзҡ„еҚұжңәжӮ„然жқҘиўӯпјҢеҚҺдёәгҖҒйҳҝйҮҢгҖҒеҜҢеЈ«еә·вҖҰвҖҰзӣёз»§дј жқҘж¶ҲжҒҜ